该模型的定义

语音识别,简单来说,就是让机器能够听懂人类语言的技术。它的任务是将人类语音中的词汇内容转换为计算机可读的文本形式。想象一下,你对着手机说出“打开天气预报”,手机迅速理解你的指令并完成相应操作,这其中就离不开语音识别技术的支持。

技术原理

特征提取
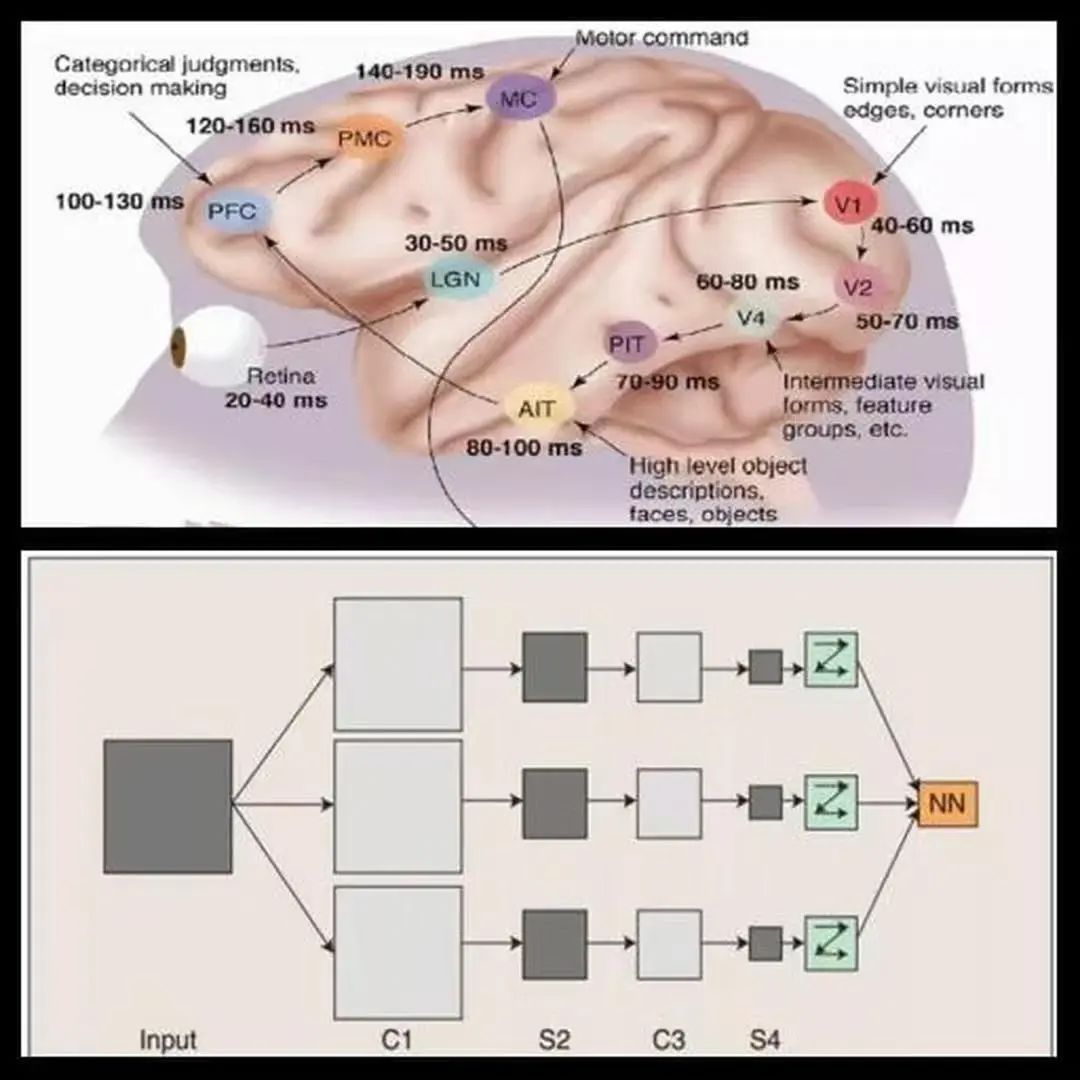
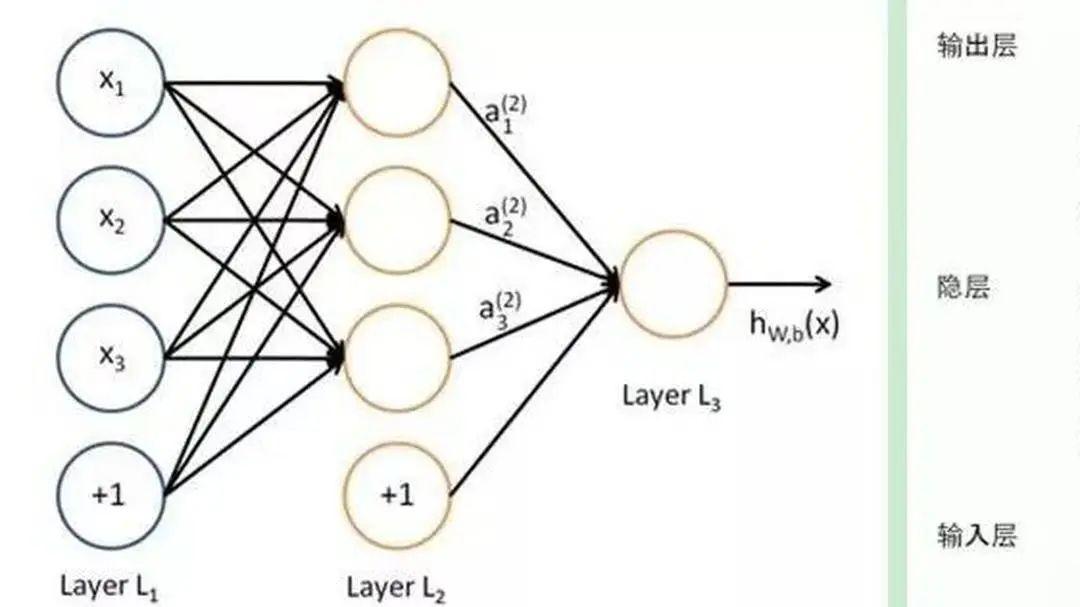
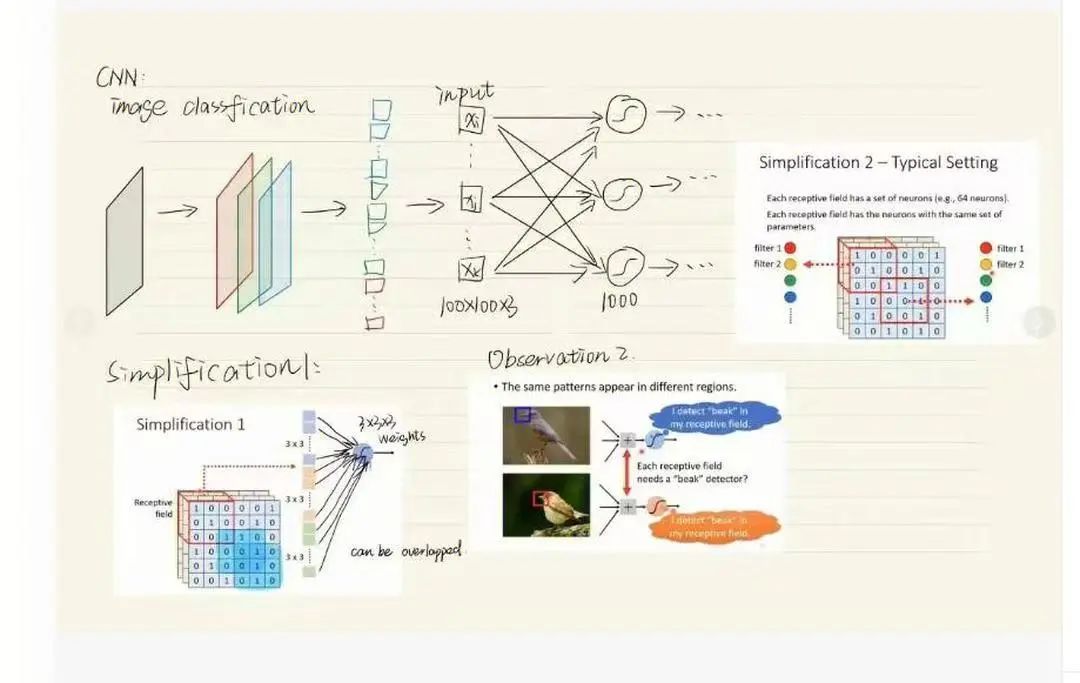
首先,将语音信号进行预处理,转化为模型能够处理的特征表示。传统方法需要人工设计复杂的特征提取算法,而端到端模型利用卷积神经网络(CNN)强大的特征提取能力,自动从原始语音信号中提取出有用的特征。CNN通过卷积层和池化层,可以有效地捕捉语音信号中的局部特征和时频特性。

序列建模
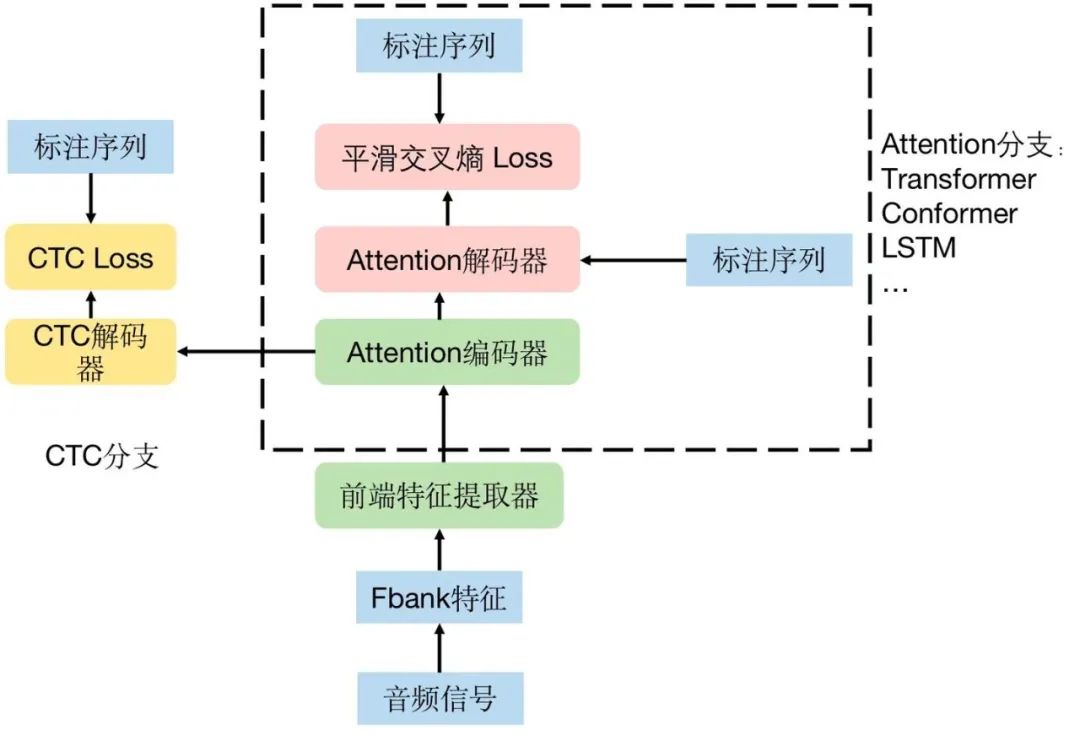
语音是一种时间序列数据,为了处理这种序列信息,循环神经网络(RNN)及其变体发挥了重要作用。RNN能够对时间序列中的前后依赖关系进行建模,LSTM和GRU则进一步解决了RNN在处理长序列时的梯度消失和梯度爆炸问题,使得模型能够更好地记住长时间跨度的信息。它们可以根据语音信号的前后顺序,逐步理解语音的语义内容。
解码与输出
模型最后通过全连接层和softmax函数,将提取到的特征和学习到的序列信息转化为文本输出。softmax函数会计算每个可能字符或单词的概率,选择概率最高的作为识别结果。同时,为了提高识别的准确性,还会使用一些解码算法,如贪心搜索、束搜索等。

该模型的优势


01
02

03

应用领域与案例


智能语音助手
像苹果的Siri、亚马逊的Alexa和小米的小爱同学等,都广泛应用了端到端的语音识别技术。用户可以通过语音与这些智能助手进行自然交互,查询信息、控制设备、设置提醒等,极大地提升了用户体验。
医疗领域
医生可以通过语音识别系统快速记录病历,避免了繁琐的手动输入过程,提高了工作效率。同时,在医疗影像诊断等领域,语音识别也有助于医生更方便地与系统交互,查看和分析患者的影像资料。
教育行业
在线教育平台利用语音识别技术实现了智能辅导和口语评测功能。学生可以通过语音回答问题,系统能够实时识别并给出反馈,帮助学生提高口语表达能力。

挑战与未来期望

尽管端到端深度学习模型在语音识别领域取得了巨大成功,但仍然面临一些挑战。例如,模型对大规模高质量标注数据的依赖,训练成本较高;在极端嘈杂环境或小语种语音识别方面,性能还有待进一步提升。
然而,随着技术的不断发展,我们对未来充满信心。一方面,新的深度学习算法和模型架构不断涌现,有望解决当前面临的问题。另一方面,硬件技术的进步,如GPU性能的提升和边缘计算设备的发展,将为语音识别技术的应用提供更强大的支持。未来,语音识别技术将更加智能、更加普及,为人们的生活带来更多的便利和惊喜。
语音识别中的端到端深度学习模型是一项具有革命性意义的技术,它正在改变我们与机器交互的方式,开启人机协同的新篇章。相信在不久的将来,它会在更多领域绽放光彩,创造出无限可能。
【END】
部分图文来源于网络
本期编辑:郑雨泓
栏目策划:李清旭
责任编辑:张家乐
审 核:曹晏宁