“鹏城·星语”
“鹏城·星语”是鹏城实验室牵头研发的语音识别系统开发工具链,针对多语言语音识别领域的典型问题进行特定优化,支持包括数据处理、模型训练、高效推理、模型微调及服务部署在内的整个语音识别流水线。“鹏城·星语”基于新一代Kaldi平台的icefall项目进行开发,改进了原本基于recipe的设计,通过解耦功能代码和参数配置,实现了一份代码适配所有ASR语种,显著提升多语言语音识别系统的开发效率。此外,“鹏城·星语”集成了RNN-T架构和Zipformer编码器,相比Transformer架构在训练效率和推理性能上均有大幅提升。
模型架构
“鹏城·星语”采用RNN-T架构,由Encoder、Decoder和Joiner三个模块组成。Encoder负责对输入的语音特征进行编码,Decoder负责生成每个时间步的预测内容,Joiner将Encoder和Decoder的输出结合,计算最终的概率分布,用来预测当前时间步的输出。语音编码器采用Zipformer,相比Conformer、Squeezeformer等主流模型具有效果更好、计算更快、更省内存等优点。此外,为缓解多语言语音识别训练中的跨语言干扰问题,通过替换<SOS> token的方式,将语言标签无缝集成到RNN-T架构的Decoder模块中:
方案验证
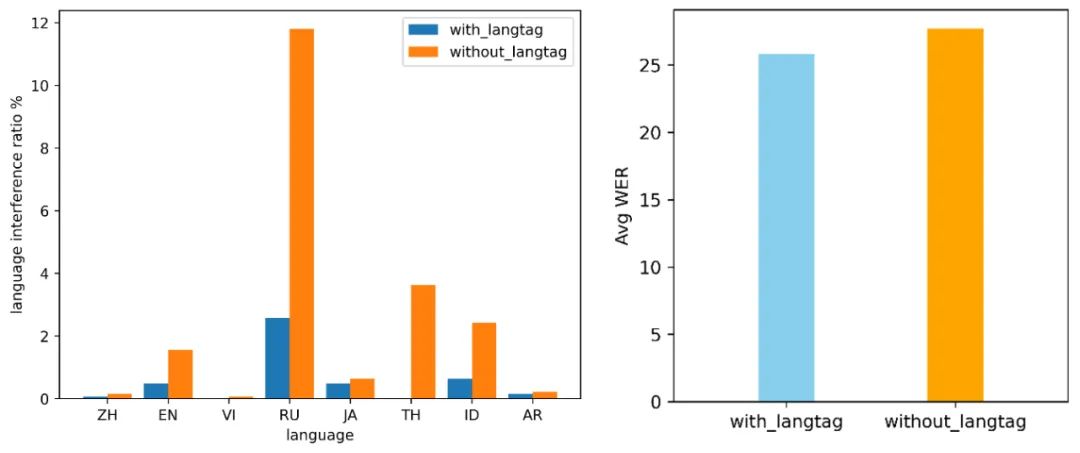
为验证方案有效性,研发团队初步构建了中文、英语、俄语、越南语、日语、泰语、印尼语和阿拉伯语共8个语种的数据集(其中大部分为开源数据,少量定制数据),每个语种取50小时数据针对语言标签进行对比实验:
性能表现
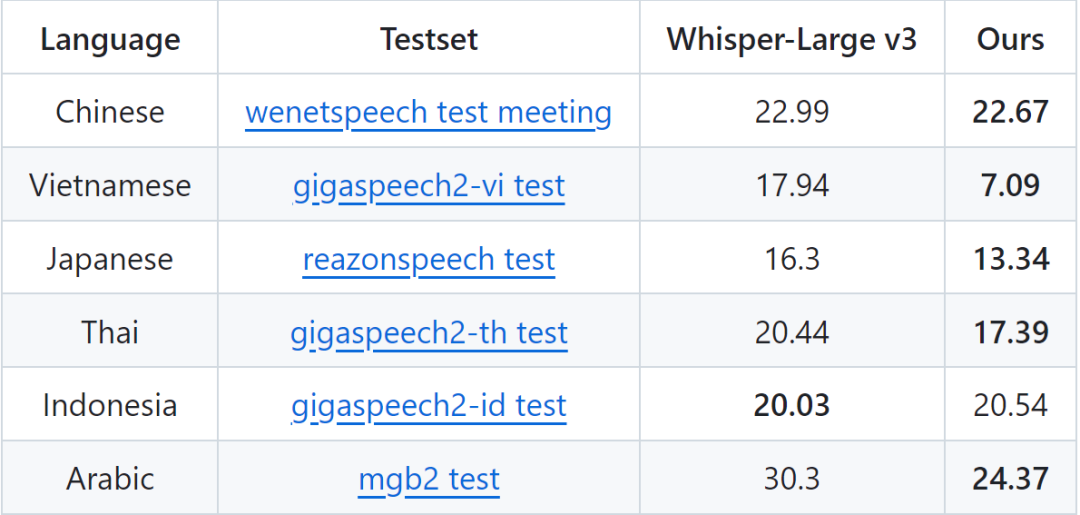
为评估模型的多语言语音识别能力,将每个语种的数据量扩展为2000小时左右进行流式训练,并在对应的开源测试集上进行测试。结果以Whisper-Large v3(非流式模型)五分之一的参数量在6个语种上取得了与其相当或更好的性能,其中在越南语、阿拉伯语、日语和泰语上的表现显著优于Whisper-Large v3:
未来计划
目前发布的“鹏城·星语”模型是支持8种语言的抢先体验版,项目还在持续开发中,未来将支持更多的“一带一路”语言,探索更多的多语言语音识别技术,并持续输出更优质的多语言语音识别模型。
附 Whisper 模型简介
Whisper是OpenAI研发并开源的一个语音识别模型,参数量从39M到1550M不等,支持包括中文在内的100多种语言。该模型基于Transformer的Encoder-Decoder结构,通过68 万小时的多语言、多任务学习,实现了语音识别、语音翻译以及语种识别等功能。
合作
yangb05@pcl.ac.cn