-FireRedASR: Open-Source Industrial-Grade Mandarin SpeechRecognition Models from Encoder-Decoder to LLM Integration
Kai-Tuo Xu, Feng-Long Xie, Xu Tang, Yao Hu
Xiaohongshu Inc.
小红书公司
编者:小红书接载了Tiktok美国数百万“难民”涌入,无意间架起了美国于中国底层百姓网民全面交流:从歌手、园艺、日常家庭起居生活教育运动全方位的交流,中文普通话和英语语言沟通是美国小红书网民的首要工具。小红书做了很多功课,用于语音识别模型FireRedASR起了关键作用。
摘要
FireRedASR是一个大规模自动语音识别系统。(ASR)模型用于普通话,旨在满足各种应用中卓越性能和最佳效率的多样要求。FireRedASR包括两个变体:1)FireRedASR-LLM:旨在实现最先进性能(SOTA)并实现无缝端到端的语音交互。它采用了一个利用大型语言模型(LLM)能力的编码器-适配器LLM框架。在公开的中文基准测试中,FireRedASR-LLM(8.3B参数)的平均字符错误率(CER)为3.05%,超过了最新的SOTA 3.33%,相对CER降低了8.4%。它在工业级基线上展示了优越的泛化能力,在多源中文ASR场景中实现了24%-40%的CER降低,如视频、实况和智能助手。2)FireRedASR-AED:设计旨在平衡高性能和计算效率,并作为LLM-based语音模型中的有效语音表示模块。它采用基于注意力的编码器-解码器(AED)架构。在公开的普通话基准测试上,FireRedASR-AED(1.1B参数)实现了平均CER为3.18%,略逊于FireRedASR-LLM,但仍优于拥有超过12B参数的最新SOTA模型。它提供了更紧凑的尺寸,适用于资源受限的应用程序。此外,两种模型在中文方言和英文语音基准上均取得了竞争力的结果,并在歌词识别方面表现出色。为推动语音处理领域的研究,我们在https://github.com/FireRedTeam/FireRedASR上发布了我们的模型和推理代码。
公共普通话ASR基准评估对比
目录
1简介
2FIREREDASR
2.1FireRed ASR-AED:基于注意力的编码器-解码器ASR模型
2.2FireRedASR-LLM:基于编码器适配器-LLM的自动语音识别模型
3评估
3.1对公开普通话ASR基准的评估
3.2对多源普通话演讲和歌唱基准的评估
3.3评估公共中国方言和英文自动语音识别基准
4讨论
5结论
参考文献
1简介
自动语音识别(ASR)在近年来发展迅速,已成为智能语音交互和多媒体内容理解中的重要组成部分。最近ASR的进展导致了几个大规模模型的出现,如Whisper、Qwen-Audio、SenseVoice和Seed-ASR,显示了从拥有数百万参数的端到端模型到更大规模模型和预训练文本LLM整合的范式转变。
尽管它们具有令人印象深刻的功能和更大的模型尺寸,但它们在实际应用中面临着重大限制。一些模型优先考虑多语言和多任务能力,导致对汉语等特定语言性能表现不佳。其他一些虽然显示出有希望的结果,但由于其闭源特性而受限,限制了社区驱动的改进和学术研究。现代语音交互系统的增长需求,由GPT-4o[20, 21]强调,进一步突显了开源、高性能的中文ASR解决方案的需求。
为了解决这些局限性,在本技术报告中,我们介绍了FireRedASR,这是一个用于普通话自动语音识别的大规模模型系列。为了满足在各种应用场景中性能和效率的不同需求,FireRedASR包括两个变种:FireRedASR-LLM和FireRedASR-AED。FireRedASR-LLM采用了创新的编码器-适配器-LLM框架,包括83亿个参数,以提高识别精度的边界。该模型特别适用于精度至关重要且计算资源不是主要约束的场景。另一方面,FireRedASR-AED旨在平衡卓越性能和最佳效率。它采用了基于注意力的编码器-解码器(AED)架构,具有高达11亿个参数。除了作为独立使用外,FireRedASR-AED还作为更大的基于LLM的语音框架中的关键语音表示组件。我们工作的关键贡献包括:
l具有高准确性和高效性的模型:在公开的中文基准测试中,FireRedASRLLM实现了平均字符错误率(CER)为3.05%,超过之前的最先进模型(Seed-ASR)的3.33%,相对减少了8.4%。同时,FireRedASR-AED实现了3.18%的CER,优于参数显著较少的Seed-ASR(超过12亿参数)。这些结果突显了我们模型在保持高效性的同时实现卓越准确性的能力。在各种实际场景中,包括短视频、直播流、自动字幕、语音输入和智能助手等,我们的模型展现出卓越的性能,相对于流行的开源基准和领先的商业解决方案,实现了24%-40%的相对CER降低(CERR)。
l多功能的识别能力:这两个变体展示了出色的多功能性,不仅在标准的普通话语音识别上表现出色,而且在中国方言和英语演讲基准上也具有竞争力的结果。值得注意的是,与工业级基线相比,它们在歌词识别方面实现了50%-67%的CERR。
l全面开源发布:我们通过发布我们的模型系列,包括预训练权重和高效推断代码来为研究社区做出贡献。这一开源发布旨在加速语音处理领域的研究进展,并实现现代端到端语音交互系统的更广泛的应用。
本报告的其余部分组织如下:第2节描述了FireRedASR-AED和FireRedASR-LLM的架构,以及训练数据和优化策略。第3节介绍了在各种基准测试和实际场景中与最近发布的大规模ASR模型相比的全面评估结果。第4节讨论了导致我们卓越性能的关键因素。第5节总结了报告。
2FireRedASR
在本部分中,我们将介绍我们两个ASR模型FireRedASR-AED和FireRedASR-LLM的架构细节和方法论。FireRedASR-AED遵循传统的基于注意力的编码器-解码器架构,而FireRedASR-LLM建立在利用LLM技术进行ASR的编码器适配器架构上。这两个模型在输入特征处理和声学编码策略上有相似之处,但在对令牌序列建模的方法上有所不同。
2.1FireRed ASR-AED:基于注意力的编码器-解码器ASR模型
FireRed ASR-AED采用了端到端架构,结合了基于Conformer的编码器。
使用基于Transformer的解码器(Dec)[24, 25]。这种设计选择利用了Conformer对语音特征中的局部和全局依赖关系进行建模的能力,以及Transformer在序列转换中的有效性。FireRedASR-AED的整体架构如图1(右下角)所示。
训练数据:训练语料库包括约70,000小时的音频数据,主要是高质量的普通话语音。与Whisper中使用的弱标记数据集不同,我们的大部分数据是由专业注释者手动转录的,确保转录准确性和可靠性。该数据集还包括约11,000小时的英文语音数据,以增强英文语音识别的能力。
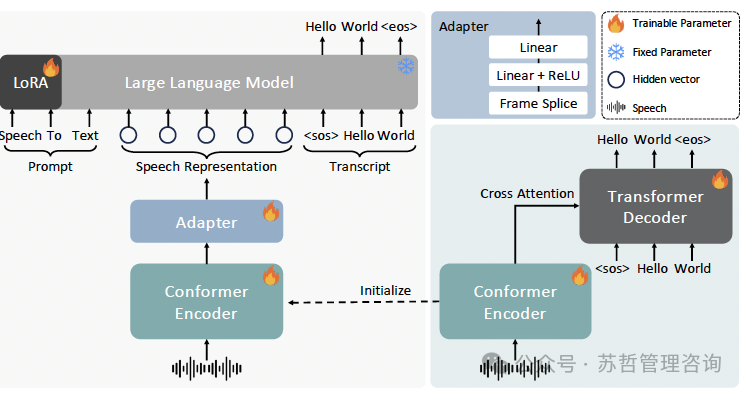
图1:FireRedASR-LLM(左侧)、FireRedASR-AED(右下角)、以及适配器的架构。
输入特征:输入特征是从25ms窗口中提取的80维对数梅尔滤波器组成的(Fbank),帧移为10ms,紧接着进行全局均值和方差归一化。
编码器结构:编码器由两个主要组件组成:一个子采样模块和一个堆叠的Conformer块。子采样模块采用两个顺序卷积层,每个的步幅为2,卷积核大小为3,接着是ReLU激活函数。这种配置将时间分辨率从每帧的10毫秒降低到40毫秒,有效管理计算复杂度同时保留重要的声学信息。子采样特征然后经过一系列Conformer块处理。每个Conformer块包含四个主要组件:两个类似Macaron风格的前馈模块分别位于块的开头和结尾,一个多头自注意力模块结合相对位置编码,以及一个带有门控线性单元(GLU)和层标准化的卷积模块。所有的1-D深度卷积的核大小均设置为33。这种结构能有效地建模语音信号中的本地和全局依赖关系,同时保持计算效率。
解码器结构:解码器遵循标准的Transformer架构,具有几个关键设计选择。它采用固定的正弦位置编码,并在输入和输出标记嵌入之间实现权重绑定,以降低模型复杂性。每个Transformer块由三个主要组件组成:多头自注意力模块,多头交叉注意力模块和逐位置前馈模块,所有这些模块均利用预归一化残差单元来增强训练稳定性和梯度流。
分词:我们采用混合分词策略:对中文文本使用中文字符,对英文文本使用基于字节对编码(BPE)的令牌级别方法。总词汇量为7,832,包括1,000个英文BPE令牌,6,827个中文字符和5个特殊令牌。
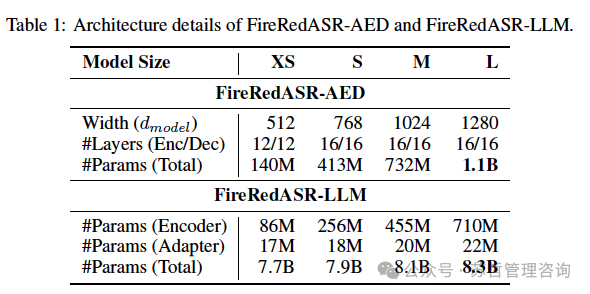
我们研究了不同尺寸的FireRedASR-AED,详细的架构配置见表1,其中#Params表示参数数量。除非另有说明,FireRedASR-AED指的是FireRedASR-AED-L。
2.2FireRedASR-LLM:基于编码器适配器-LLM的自动语音识别模型
FireRedASR-LLM也是一个端到端的ASR模型,但旨在将FireRedASR-AED的强大语音处理能力与LLM的优越语言能力进行整合。它包括三个核心组件:基于Conformer的音频编码器,轻量级音频文本对齐适配器和预训练的基于文本的LLM,形成我们所称的编码器-适配器-LLM架构。FireRedASR-LLM的整体架构如图1(左)所示。
表1:FireRedASR-AED和FireRedASR-LLM的架构细节。
输入特征和编码器:FireRedASR-LLM使用与FireRedASR-AED相同的训练数据、输入特征和处理方法。FireRedASR-LLM的编码器从FireRedASR-AED的编码器中初始化预训练的权重。该编码器生成连续表示,封装了输入语音的声学和语义特征。
适配器结构和功能:为了将音频编码器与基于文本的LLM无缝集成,采用了适配器网络。该适配器将编码器的输出转换为LLM的语义空间,使LLM能够准确识别输入语音中对应的文本内容。适配器由一个简单但有效的线性-ReLU-线性网络组成,将编码器的输出维度投影到与LLM的输入嵌入维度相匹配。即使在从10ms到40ms的时间下采样之后,编码器的输出仍然对于LLM来说太长,无法高效处理。因此,我们在适配器的开始处加入了额外的帧拼接操作。该操作进一步将帧的时间分辨率从40ms降低到每帧80ms,从而减少序列长度,提高LLM的计算效率。
LLM初始化和处理:FireRedASR-LLM的LLM组件使用Qwen2-7B-Instruct [28]的预训练权重进行初始化,这是一个知名的开源LLM。在训练过程中,FireRedASR-LLM的输入包括一个三元组:(提示,语音,转录)。编码器和适配器生成语音嵌入ES,而提示和转录通过LLM进行标记化和嵌入,生成提示嵌入EP和转录嵌入ET。这些嵌入被连接为(EP,ES,ET),并由LLM的后续层进行处理。在推断过程中,输入被简化为(EP,ES),使LLM能够执行下一个标记预测,并从语音生成识别文本。
训练策略:我们采用精心设计的训练策略,平衡了对预训练能力的适应和保留:编码器和适配器是完全可训练的,而大部分LLM参数保持不变。我们加入可训练的LLM低秩适应(LoRA)[29]来高效微调LLM。这种策略确保编码器和适配器经过充分训练,将语音特征映射到LLM的语义空间,同时保留其预训练能力。训练目标基于交叉熵损失,损失仅在输入的转录部分计算,忽略提示和语音嵌入。
我们研究了各种规模的FireRedASR-LLM,详细的架构配置见表1。除非另有说明,FireRedASR-LLM指的是FireRedASR-LLM-L。
3评估
在这一部分中,我们对FireRedASR-LLM和FireRedASR-AED模型进行了全面评估,重点关注它们在普通话语音识别中的表现。评估分为三个部分,以系统评估模型的能力和泛化能力。
首先,我们使用几个公开的普通话测试集来对我们的模型进行基准测试,以在标准化条件下建立基准性能。其次,我们评估它们在多源普通话语音测试集上的表现,以验证它们在真实环境中的稳健性。另外,我们评估模型在歌词识别上的有效性,这对于特定的工业应用至关重要。第三,我们评估模型在方言和英语语音识别上的表现,以展示它们在标准普通话之外更广泛应用的潜力。
指标:我们使用字符错误率(CER)来评估中文语音和歌词识别,使用词错误率(WER)来评估英文。
3.1对公开普通话ASR基准的评估
我们将FireRedASR-LLM和FireRedASR-AED与几种最近发布的大型ASR模型进行了基准测试,包括Seed-ASR [5],SenseVoice-L [4],Qwen-Audio [2],ParaformerLarge [30]和Whisper-Large-v3 [1]。评估是在四个广泛使用的公共数据集上进行的。
中文普通话ASR测试集: 1) AISHELL-1 [31]测试集(aishell1); 2) AISHELL-2 [32] iOS版本测试集(aishell2); 3) WenetSpeech [33]互联网领域测试集(ws_net); 4) WenetSpeech会议领域测试集(ws_meeting).比较模型的结果均来自它们各自的发表内容,Whisper-Large-v3结果取自SenseVoice-L [4],Qwen-Audio的WenetSpeech结果来自Seed-ASR [5].
如表2所示,FireRedASR-LLM和FireRedASR-AED均胜过Seed-ASR。
FireRedASR-LLM相对于SeedASR在所有四个测试集(平均-4)上的平均字符错误率(CER)降低了8.4%。Seed-ASR是一种最先进的大规模ASR模型,但不是开源的,在其自监督学习阶段训练了770万小时,在监督微调阶段训练了56.2万小时,其编码器中有近20亿参数,在其LLM中有超过100亿参数。相比之下,FireRedASR-AED只包含了11亿参数,FireRedASR-LLM包含了83亿参数,突显了我们模型的架构、训练策略和数据集的有效性。与许多开源模型相比,FireRedASR-AED在比Whisper-Large-v3、SenseVoice-L和Qwen-Audio更少的参数下实现了29%-68%的CER降低。
观察到的规模律:最近LLM研究表明,模型性能通常随着模型尺寸的增加而改善,即所谓的规模律[34]。如第3节所示,我们研究了具有不同模型尺寸的模型的规模行为,详细信息见表格。
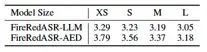
对于FireRedASR-AED,我们会逐步将模型大小从140M、413M、732M逐渐扩展。
1.1B参数。随着模型规模的增加,性能持续提高,从XS到S,S到M,M到L配置时实现的CERR分别为6.1%,5.3%和5.6%。对于FireRedASR-LLM,我们专注于增加编码器的规模,同时保持LLM骨干不变。编码器的大小从86M增加到710M参数,适配器参数略有变化(从17M到22M)。这展示了类似的扩展模式,并导致一致的性能提升,从XS(3.29%)到L(3.05%)配置的总体CERR为7.3%。这些结果证明了我们的扩展策略的有效性,并表明具有更大模型容量的进一步改进潜力。
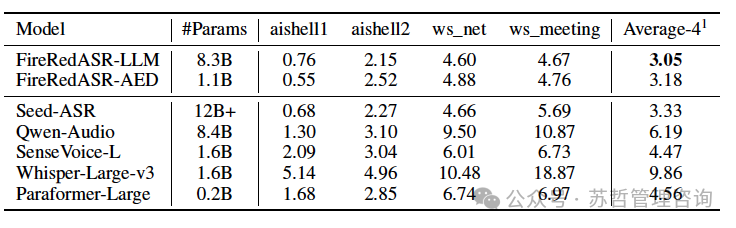
表2:FireRedASR-LLM、FireRedASR-AED和其他发布的大型ASR模型在四个公共普通话ASR测试集上的字符错误率(CER%)比较。
Seed-ASR报告了六个公共普通话数据集(Average-6)的平均CER,包括我们讨论的这四个数据集以及AISHELL-2的Android和Mic版本。我们聚焦于Average-4,因为后两者与iOS版本仅在录音设备上有所不同,而iOS版本在文献中更常被评估。为了直接比较,我们的FireRedASR-LLM实现了2.86%的Average-6 CER,优于Seed-ASR的2.98%。
表3:FireRedASR-LLM和FireRedASR-AED在四个公开的普通话ASR测试集上,不同模型尺寸的平均CER比较。
3.2对多源普通话演讲和歌唱基准的评估
为了全面评估FireRedASR-LLM和FireRedASR-AED的能力,我们对多源普通话语音识别和歌词识别进行了广泛的测试。语音测试集从五个不同的场景精心策划而来:短视频、直播流、自动字幕、语音输入和智能助手,确保涵盖了真实世界应用的广泛领域。我们计算跨这些场景的平均字符错误率(CER),以确保对其进行健壮的评估。此外,我们从短视频中构建了一个歌词测试集,以评估歌词识别的性能,这对于各种实际应用是一个关键要求。
为了进行比较分析,我们选择两类基线系统:1) Paraformer-Large,这是普遍被广泛采用的开源模型,在普通话语音处理社区中使用;2)来自领先的普通话语音识别提供商(简称ProviderA)的商业ASR服务,包括它们的基础版本(ProviderA-Base)和大型版本(ProviderA-Large)。
如表4所示,在语音识别任务中,FireRedASR-LLM以3.48%的字符错误率取得最佳性能,紧随其后的是FireRedASR-AED,其字符错误率为3.74%。这两个模型显著优于商业和开源基线,FireRedASR-LLM相对于ProviderA-Large(CER 4.56%)的相对改进幅度为23.7%,相对于Paraformer-Large(CER 5.80%)的相对改进幅度为38.6%。
在歌词识别任务中,性能差距变得更加显著。FireRedASR-LLM保持着出色的性能,字符错误率(CER)为7.05%,而ProviderA-Large和Paraformer-Large的CER分别为14.16%和21.19%,对应的相对改进率(CERR)分别为50.2%和66.7%。这一在歌词识别方面的显著改进展示了我们模型在处理具有挑战性的声学条件和不同的声乐风格上的强大能力。
FireRedASR-AED在语音和歌词识别任务中也明显优于其他基准系统。这些结果令人信服地表明,FireRedASR-AED和FireRedASR-LLM都实现了卓越的工业级性能,在处理多样的声学环境和诸如歌词识别之类的专业任务方面具有特别优势。
表4:FireRedASR-LLM、FireRedASR-AED和基线ASR模型在多源普通话演讲和演唱测试集上的CER和相对CER减少率(CERR)比较。CERR值是相对于FireRedASR-LLM性能计算的。
演讲唱歌
3.3评估公共中国方言和英文自动语音识别基准
FireRedASR-LLM和FireRedASR-AED展示了强大的泛化能力,尽管主要设计用于普通话ASR,在中国方言和英语语音识别方面取得了令人印象深刻的结果。为了展示模型超越标准普通话的有效性,我们在几个广泛采用的公共基准上评估它们的性能。据我们所知,我们将我们的模型与先前的SOTA开源模型在相应的测试集上进行比较。
针对中文方言语音识别,我们在KeSpeech [35]测试集上评估了我们的模型。根据最近发布的报告[36],包括Baichuan-omni、Qwen2Audio-Instruct和Whisper-Large-v3(参数尺寸分别为7B+、7B+和1.5B)在KeSpeech上的平均CER分别为6.7%、9.9%和44%。如表5所示,FireRedASRLLM和FireRedASR-AED显著优于这些模型,分别实现了3.56%和4.48%的CER。
对于英语语音识别,我们在广泛采用的LibriSpeech[37]测试集(test-clean和test-other)上评估我们的模型。Whisper-Large-v3是一个流行的开源多语言ASR模型,经过500万小时的音频数据训练,在test-clean和test-other上分别实现了1.82%和3.50%的WER,如[4]所报告。我们的模型展现了竞争性性能:FireRedASR-LLM在两个测试集上的WER分别为1.73%和3.67%,而FireRedASR-AED在相应的测试集上的WER分别为1.93%和4.44%。
表5:在中国方言测试组(KeSpeech)和英语测试组(LibriSpeech)上的ASR性能比较。KeSpeech的结果以CER(%)报告,而LibriSpeech的结果以WER(%)报告。先前的SOTA开源结果来源于[36,1,4]。
4讨论
在这一部分,我们探讨了为什么我们的FireRedASR模型胜过竞争对手模型的原因。我们将优越的性能归因于以下三个因素:
高质量和多样化的训练数据:我们的训练语料库主要由从现实场景中收集到的专业转录的音频组成,这提供了比受控环境中传统阅读风格录音更有价值的训练信号。这个数据集涵盖了丰富的声学条件、说话者、口音和内容领域的变化,总共达数万小时。这种多样性和规模使我们的模型能够学习到强大的语音表示和语言模式,从而导致强大的泛化能力。我们的实证研究表明,一千小时的高质量、人工标注的数据比一万小时的弱标注数据(例如来自视频字幕、OCR结果或合奏ASR输出)产生更好的结果,解释了我们相对于Whisper风格模型的优势。此外,我们语料库中包含的歌唱数据对我们在处理音乐内容方面相对于基线模型的显著性能改进起到了一定的贡献。
优化训练策略:在将FireRedASR-AED从140M扩展到1.1B参数时,我们确定正则化和学习率是影响模型收敛的关键因素。我们开发了一种渐进式正则化训练策略:最初在不使用正则化技术(dropout和SpecAugment [38])的情况下进行训练,以实现快速收敛,然后在过拟合趋势出现时逐渐引入更强的正则化。这种方法使得FireRedASR-AED 1.1B的训练取得了成功,表现出优越的结果。这种策略对于参数为732M、413M和140M的小型模型也证明有益。此外,更大的模型受益于降低学习率,因此调整该参数以实现最佳性能至关重要。
高效的ASR框架:我们的架构选择是通过广泛的实验和先前的工作得出的。虽然我们先前基于Two-pass Transducer的模型在各种参数数量为百万级的ASR模型中取得了合理的性能,但它存在着扩展限制和对超参数高度敏感,其中预测网络组件容易过拟合。与FireRedASR中使用的交叉熵损失相比,Transducer方法也导致了显著的内存开销。受到Whisper等最新进展的启发,同时解决这些限制,我们采用了一个基于注意力的编码器-解码器架构,结合我们实现的Conformer和Transformer。此外,我们还采用了一种简单但有效的适配器设计,灵感来源于最近的研究作品,促进了高效的模型适应和研究迭代。
5结论
我们提出了FireRedASR-LLM和FireRedASR-AED两种优化过的中文语音识别模型,经过全面评估,我们证明它们的架构、训练策略和高质量数据集可以实现最先进的性能,并保持计算效率。FireRedASR-AED表明基于注意力的编码器-解码器架构仍然具有很高的竞争力,而FireRedASR-LLM则利用编码器适配器LLM框架展示了将LLM能力融合到语音识别系统中的潜力。我们的广泛评估结果确认了两种模型在多个方面的强劲性能:在公开的中文基准测试上取得了最先进的结果,在各种真实场景中表现突出,在歌词识别精度方面表现出色,并展示了对中文方言和英文语音识别的稳健泛化能力。通过释放模型权重和推理代码,我们旨在为语音处理研究的进展做出贡献。未来的工作将重点致力于进一步提高性能并扩展对更多语言和不同任务的支持。
参考文献
省略。。。。。。