











语音识别是将人的语音信号转换成文字的过程,隐马尔可夫模型(Hidden Markov Model,HMM)是语音识别领域中应用广泛的方法之一,用于描述一个含有隐含未知参数的马尔可夫过程。它由美国数学家鲍姆等人在20世纪60年代末至70年代初提出,后被广泛应用于语音识别、自然语言处理等领域。

基本原理

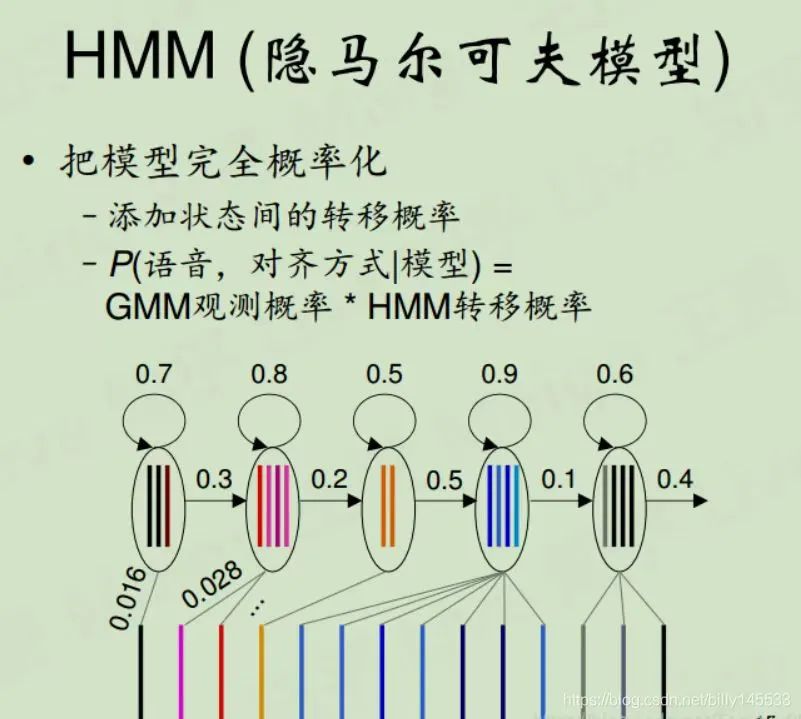
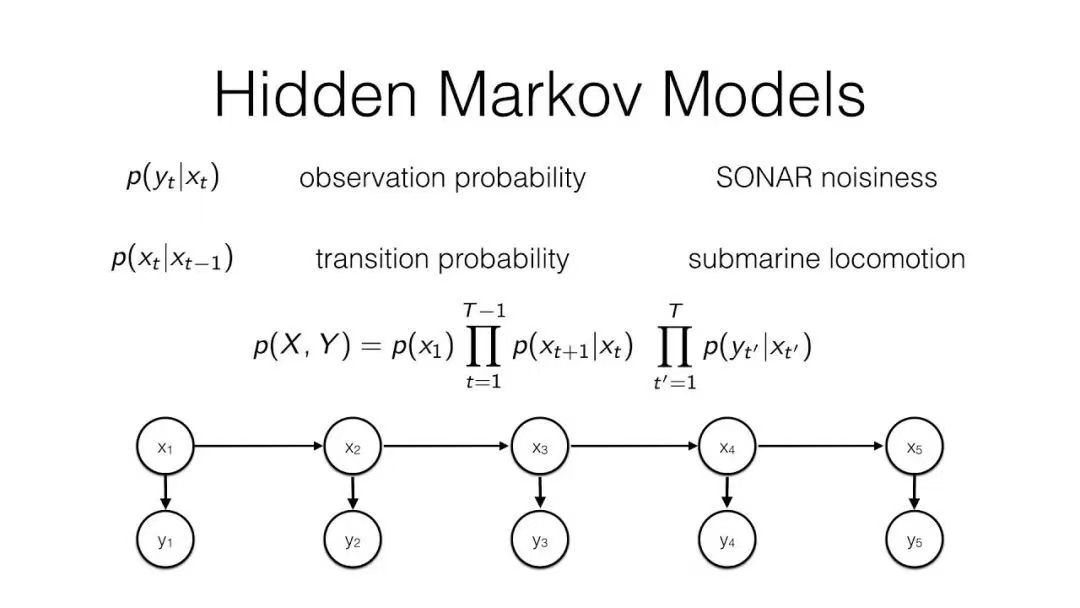
双重随机过程:HMM是一个双重随机过程,包括一个隐藏的马尔可夫链和一个与隐藏状态相关联的观测序列。隐藏的马尔可夫链由状态集合、状态转移概率矩阵和初始状态概率分布组成,描述了不可观测的状态转移过程。观测序列根据隐藏状态按照观测概率矩阵生成。




关键假设:HMM有两个关键假设。一是马尔可夫假设,即当前状态只与前一状态有关,与更前面的状态无关。二是观测独立性假设,即每个观测值仅由当前隐藏状态决定,与其他观测值和隐藏状态无关。

模型参数

状态集合:所有可能的隐藏状态的集合,在语音识别中,可将不同的音素或音素组合对应到不同状态。
观测集合:所有可能观测到的符号或数据的集合,语音识别中常采用梅尔频率倒谱系数(MFCC)等作为观测值。
状态转移概率矩阵:表示从一个隐藏状态转移到另一个隐藏状态的概率分布。
观测概率矩阵:描述在每个隐藏状态下生成各个观测值的概率。
初始状态概率分布:模型开始时处于各个隐藏状态的概率。

应用过程


1.语音信号预处理
原始语音信号易受环境噪声干扰,所以第一步是对其进行预处理。通过预加重提升高频分量,再利用分帧与加窗技术将连续语音切分为短帧,为后续分析做准备。

2.特征提取
从分帧后的语音信号里提取梅尔频率倒谱系数(MFCC) 、线性预测倒谱系数(LPCC)等特征参数。这些参数能有效表征语音信号特性,比如MFCC反映了人耳听觉特性,将语音频谱转化为更符合听觉感知的特征序列。

3.模型训练
准备大量带标注的语音数据,利用最大似然估计等方法,来训练隐马尔可夫模型。在训练中确定状态转移概率矩阵,即从一个隐状态转移到另一个隐状态的概率;以及观测概率矩阵,也就是每个隐状态产生对应观测值的概率。

4.语音识别
将待识别语音经预处理和特征提取后,输入已训练好的HMM中。运用维特比算法进行解码,找出最有可能的隐状态序列,再根据预先设定的规则,将其转换为对应的文本信息,完成语音到文字的转换。


优劣综述

01
优点

对序列数据的建模能力强:能够很好地处理语音这种具有时序特性的数据,捕捉语音信号中的动态变化和统计规律。
可解释性相对较好:模型的各个参数具有明确的物理意义,如状态转移概率和观测概率等,有助于理解语音生成和识别的过程。
有成熟的训练和解码算法:鲍姆-韦尔奇算法和维特比算法等为模型的训练和应用提供了有效的计算方法,使得HMM在实际中能够快速准确地进行语音识别。

02
缺点

观测独立性假设的局限性:在实际语音中,相邻的观测值之间往往存在一定的相关性,而HMM的观测独立性假设忽略了这种相关性,可能导致模型对语音数据的描述不够准确。
状态数量的确定困难:模型的性能对状态数量较为敏感,状态数量过多会导致模型复杂度过高、训练数据需求大且容易过拟合;状态数量过少则无法充分描述语音的变化,影响识别准确率。确定合适的状态数量通常需要大量的实验和经验。
"隐马尔可夫"模型


总结

隐马尔可夫模型在语音识别领域未来仍潜力无限。它与多模态交互技术协同,可融合视觉等信息,在智能家居、智能车载等场景,带来更自然、流畅的人机交互体验 ,为语音识别发展提供新机遇。

"隐马尔可夫"模型
END
部分图文来自于网络
本期编辑:张佳慧
栏目策划:李清旭
责任编辑:张家乐
审 核:曹晏宁