语音合成解决方案主要分为开源方案和商业方案,以下是来自人工智能提供的一点点简介:
开源库
-
gTTS (Google Text-to-Speech):
-
一个轻量级的Python库,使用Google Translate的TTS API。 -
易于使用,适合快速实现语音合成功能。 -
适合需要简单语音合成的应用。 -
pyttsx3:
-
一个跨平台的Python TTS库,支持Windows、macOS和Linux。 -
不依赖于网络连接,适合离线使用。 -
支持多种语音引擎,如SAPI5、NSSpeechSynthesizer和espeak。 -
Mozilla TTS:
-
基于深度学习的语音合成引擎,提供自然的语音输出。 -
支持多种语言和自定义语音模型训练。 -
适合需要高质量语音合成的应用。
商业API
-
Google Cloud Text-to-Speech:
-
提供高质量的语音合成服务,支持多种语言和语音。 -
提供基于WaveNet的自然语音合成。 -
需要Google Cloud账户和API密钥。 -
Amazon Polly:
-
AWS提供的语音合成服务,支持多种语言和语音。 -
提供实时流式合成和多种语音风格。 -
需要AWS账户和API密钥。 -
Microsoft Azure Cognitive Services Text-to-Speech:
-
提供高质量的语音合成,支持多种语言和语音。 -
提供自定义语音和情感语音合成功能。 -
需要Azure账户和API密钥。 -
IBM Watson Text to Speech:
-
提供多语言支持和高质量语音合成。 -
提供灵活的API和自定义语音选项。 -
需要IBM Cloud账户和API密钥。
-
安装 gtts 模块;
pip install gtts-
使用 gtts 模块生成对应文本的音频(默认为 .mp3 文件);
fromgttsimportgTTSimportos# 要转换为语音的文本text ="Hello, this is a test of the Google Text-to-Speech library."# 创建 gTTS 对象# 英语:lang='en',中文:lang='zh'tts = gTTS(text=text, lang='en', slow=False)# 保存为 MP3 文件tts.save("output.mp3")# 播放生成的音频文件(可选)# 对于 Windows 系统,可以使用以下命令播放音频os.system("start output.mp3")# 对于 macOS 系统,可以使用以下命令播放音频# os.system("afplay output.mp3")
-
安装 pydub 模块;
pip install pydubfromgttsimportgTTSfrompydubimportAudioSegmentimportosdeftext_to_wav(text, output_file):# 创建 gTTS 对象# 英语:lang='en',中文:lang='zh'# tts = gTTS(text=text, lang='en', slow=False)tts = gTTS(text=text, lang='zh', slow=False)# 临时保存为 MP3 文件temp_mp3 ="temp.mp3"tts.save(temp_mp3)# 使用 pydub 将 MP3 转换为 WAVsound = AudioSegment.from_mp3(temp_mp3)sound.export(output_file,format="wav")# 删除临时 MP3 文件os.remove(temp_mp3)print(f'Audio content written to file "{output_file}"')# 调用函数,传入文本和输出 WAV 文件路径text_to_wav("客户您好","output.wav")
-
安装 pyttsx3、pydub模块;
pip install pyttsx3 pydub-
默认根据英文生成英语语音:
importpyttsx3frompydubimportAudioSegmentimporttempfileimportos# 初始化 pyttsx3 引擎engine = pyttsx3.init()# 要转换为语音的文本text ="Hello, this is a test of the pyttsx3 text-to-speech library."# 创建临时文件withtempfile.NamedTemporaryFile(delete=False, suffix=".wav")asfp:temp_wav_path = fp.name# 保存语音到临时 WAV 文件engine.save_to_file(text, temp_wav_path)engine.runAndWait()# 确保文件已关闭后再使用 pydub 读取audio = AudioSegment.from_wav(temp_wav_path)# 保存为 WAV 文件# output_file_path = "output.wav"# audio.export(output_file_path, format="wav")# 保存为 MP3 文件output_file_path ="output.mp3"audio.export(output_file_path,format="mp3")# 删除临时文件os.remove(temp_wav_path)print(f"Audio has been saved as{output_file_path}")
-
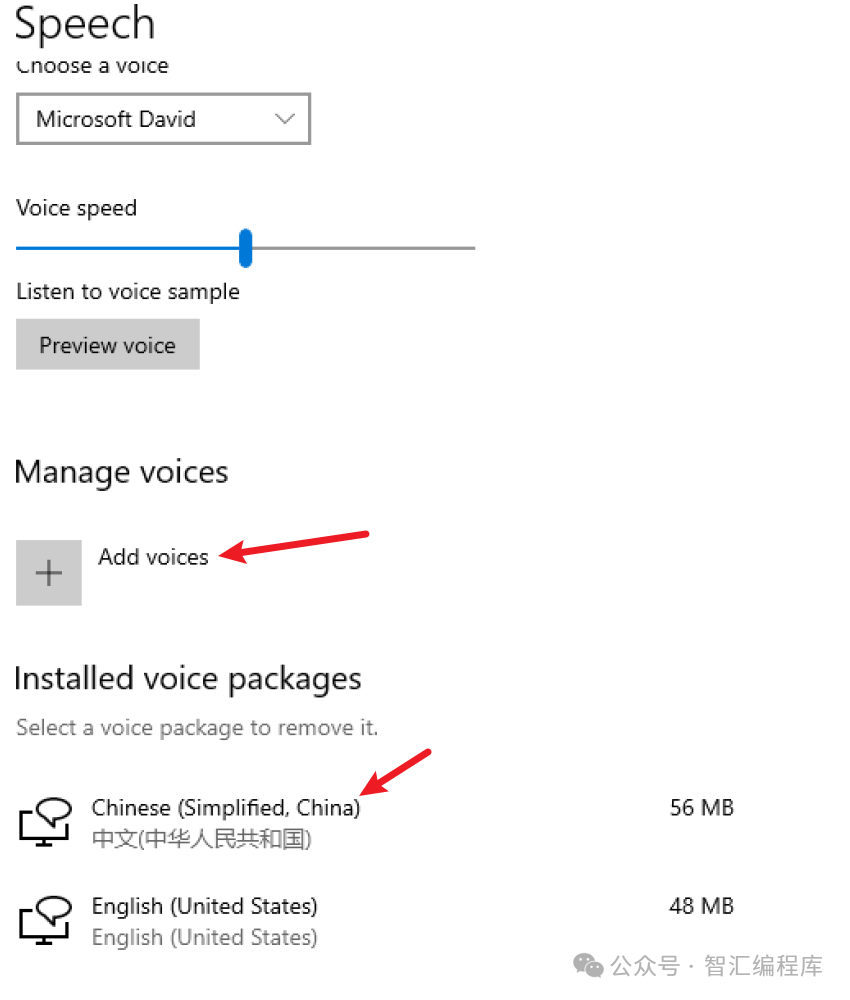
打开“设置” > “时间和语言” > “语言”。 -
添加中文(简体或繁体)语言包,并确保安装了语音功能。
importpyttsx3frompydubimportAudioSegmentimporttempfileimportos# 初始化 pyttsx3 引擎engine = pyttsx3.init()# 列出所有可用的语音voices = engine.getProperty('voices')forvoiceinvoices:print(f"Voice:{voice.name}, ID:{voice.id}, Languages:{voice.languages}")# 设置中文语音(根据系统中可用的中文语音ID)# 你需要找到支持中文的语音ID并设置chinese_voice_id =Noneforvoiceinvoices:if'zh'invoice.languages: # 检查语言代码是否包含中文chinese_voice_id = voice.idbreakifchinese_voice_id:engine.setProperty('voice', chinese_voice_id)else:print("No Chinese voice found on this system.")exit()# 要转换为语音的中文文本text ="你好,这是一个使用 pyttsx3 进行中文语音合成的测试。"# 创建临时文件withtempfile.NamedTemporaryFile(delete=False, suffix=".wav")asfp:temp_wav_path = fp.name# 保存语音到临时 WAV 文件engine.save_to_file(text, temp_wav_path)engine.runAndWait()# 确保文件已关闭后再使用 pydub 读取audio = AudioSegment.from_wav(temp_wav_path)# 保存为 WAV 文件# output_file_path = "output.wav"# audio.export(output_file_path, format="wav")# 保存为 MP3 文件output_file_path ="output.mp3"audio.export(output_file_path,format="mp3")# 删除临时文件os.remove(temp_wav_path)print(f"Audio has been saved as{output_file_path}")
-
安装必要模块;
pip install torch torchvision torchaudio-
下载源代码:
-
下载模型与配置;
-
安装依赖;
cdTTSpip install -r requirements.txt
-
代码示例:
importtorchfromTTS.TTS.utils.synthesizerimportSynthesizerfromTTS.TTS.utils.ioimportload_config# 设置模型路径和配置文件路径MODEL_PATH ="path/to/your/model.pth"CONFIG_PATH ="path/to/your/config.json"# 加载配置config = load_config(CONFIG_PATH)# 初始化合成器synthesizer = Synthesizer(MODEL_PATH,config,use_cuda=torch.cuda.is_available())# 要合成的文本text ="你好,这是一个使用 Mozilla TTS 进行语音合成的测试。"# 生成语音wav = synthesizer.tts(text)# 保存为 WAV 文件synthesizer.save_wav(wav,"output.wav")print("Audio has been saved as output.wav")
- gTTS 是一个简单易用的在线工具,适合需要快速实现多语言语音合成的项目。
- pyttsx3 是一个离线工具,适合需要在没有网络连接的环境中使用,语音质量依赖于系统的语音引擎。
- Mozilla TTS 提供了高质量的语音合成,适合需要自定义和高性能的应用,但需要更多的设置和配置。
商用解决方案我们就不说了,我们不是氪金玩家,看看有啥开源方案吧~
在 Python 中,有几种开源语音识别解决方案可供选择,这些工具可以帮助你在不依赖商业服务的情况下实现语音识别功能。以下是一些常用的开源语音识别库:
-
SpeechRecognition:
-
虽然它可以与商业 API 一起使用,但也支持开源引擎如 CMU Sphinx。 -
提供简单的接口来处理音频文件和麦克风输入。 -
Vosk:
-
一个开源的离线语音识别工具,支持多种语言。 -
提供 Python 接口,适合在嵌入式设备或需要离线处理的应用中使用。 -
支持实时语音识别和批处理模式。 -
DeepSpeech:
-
Mozilla 开发的开源语音识别引擎,基于深度学习技术。 -
提供 Python 接口和离线识别能力。 -
适合需要高准确率的应用,支持自定义模型训练。 -
PocketSphinx:
-
CMU Sphinx 的一个轻量级版本,适合在资源受限的环境中使用。 -
提供 Python 接口,支持多种语言。 -
适合简单的语音识别任务和嵌入式应用。 -
Kaldi:
-
一个功能强大的开源语音识别工具包,广泛用于学术研究。 -
提供灵活的配置和高性能,但需要较高的技术门槛。 -
虽然没有直接的 Python 接口,但可以通过第三方库进行集成。
-
安装依赖;
pip install SpeechRecognition-
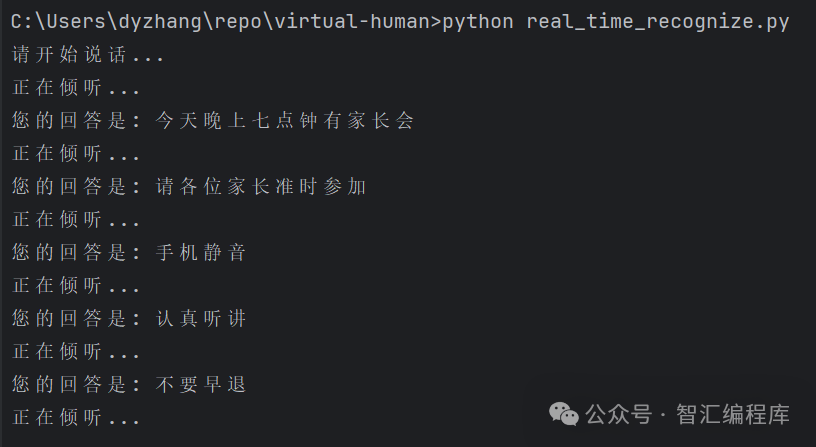
实时语音识别;
importspeech_recognitionassrdefreal_time_speech_to_text():# 创建识别器对象recognizer = sr.Recognizer()# 使用麦克风作为音频输入源withsr.Microphone(sample_rate=16000)assource:print("请开始说话...")# 调整麦克风的噪声水平recognizer.adjust_for_ambient_noise(source, duration=0.5)# 监听音频输入try:whileTrue:print("正在倾听...")audio_data = recognizer.listen(source, phrase_time_limit=10)# 使用 Google Web Speech API 进行语音识别try:text = recognizer.recognize_google(audio_data, language='zh-CN')print("您的回答是: "+ text)exceptsr.UnknownValueError:print("无法识别,继续~")exceptsr.RequestErrorase:print(f"无法识别,错误信息:{e}")exceptKeyboardInterrupt:print("实时语音识别已停止")# 调用函数进行实时语音识别real_time_speech_to_text()
-
识别音频文件;
importspeech_recognitionassrdefspeech_to_text(audio_file):# 创建识别器对象recognizer = sr.Recognizer()# 读取音频文件withsr.AudioFile(audio_file)assource:audio_data = recognizer.record(source)# 使用 Google Web Speech API 进行语音识别try:# 可识别中英文# text = recognizer.recognize_google(audio_data)# 识别中文text = recognizer.recognize_google(audio_data, language='zh-CN')print("语音文件中说的话是: "+ text)exceptsr.UnknownValueError:print("无法识别,继续~")exceptsr.RequestErrorase:print(f"无法识别,错误信息:{e}")# 调用函数,传入音频文件路径speech_to_text("output.wav")

-
下载模型;

-
安装依赖;
pip install vosk sounddevice-
编写代码;
importosimportqueueimportsysimportsounddeviceassdimportvoskimportjson# 设置模型路径model_path ="vosk-model-small-cn-0.22"# 加载模型ifnotos.path.exists(model_path):print("Please download the model from https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")exit(1)model = vosk.Model(model_path)# 创建音频队列audio_queue = queue.Queue()# 定义音频回调函数defcallback(indata, frames, time, status):ifstatus:print(status, file=sys.stderr)audio_queue.put(bytes(indata))# 设置音频流参数samplerate =16000device =None# 使用默认设备# 创建音频流withsd.RawInputStream(samplerate=samplerate, blocksize=8000, device=device, dtype='int16',channels=1, callback=callback):print("请开始说话...")# 创建识别器rec = vosk.KaldiRecognizer(model, samplerate)whileTrue:data = audio_queue.get()ifnotrec.AcceptWaveform(data):continueresult = rec.Result()text = json.loads(result).get('text','')ifnottext:continueprint("语音识别: "+ text)

-
安装依赖;
pip install numpy pyaudio-
下载模型:
-
编写代码;
importdeepspeechimportnumpyasnpimportpyaudio# 模型路径MODEL_PATH ='deepspeech-0.9.3-models.pbmm'# 替换为您的模型路径SCORER_PATH ='deepspeech-0.9.3-models.scorer'# 替换为您的 scorer 文件路径# 初始化 DeepSpeech 模型model = deepspeech.Model(MODEL_PATH)model.enableExternalScorer(SCORER_PATH)# 音频参数RATE =16000CHANNELS =1FORMAT = pyaudio.paInt16CHUNK =1024# 初始化 PyAudiop = pyaudio.PyAudio()# 打开音频流stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)print("开始实时语音识别...")try:whileTrue:# 读取音频数据data = stream.read(CHUNK)# 将音频数据转换为 numpy 数组audio_data = np.frombuffer(data, dtype=np.int16)# 进行语音识别text = model.stt(audio_data)iftext:print("识别结果:", text)exceptKeyboardInterrupt:print("停止语音识别...")# 关闭音频流stream.stop_stream()stream.close()p.terminate()