GitHub 地址:https://github.com/stepfun-ai/Step-Audio
Hugging Face:https://huggingface.co/collections/stepfun-ai/step-audio-67b33accf45735bb21131b0b
Model Scope:https://modelscope.cn/collections/Step-Audio-a47b227413534a
技术报告:https://arxiv.org/abs/2502.11946
亮点
-
1300 亿多模态理解生成一体化:单模型能实现理解生成一体化完成语音识别、语义理解、对话、语音克隆、语音生成等功能,开源千亿参数多模态模型 Step-Audio-Chat 版本。
-
高效合成数据链路:Step-Audio 突破传统 TTS 对人工采集数据的依赖,通过千亿模型的克隆和编辑能力,生成高质量的合成音频数据,实现“合成数据生成与模型训练的循环迭代”框架,并同步开源首个基于大规模合成数据训练,支持 RAP 和哼唱的指令加强版语音合成模型 Step-Audio-TTS-3B 。 -
精细语音控制:支持多种情绪(如生气,高兴,悲伤)、方言(包括粤语、四川话等)和唱歌(包括 RAP、干声哼唱)的精准调控,满足用户对多样化语音生成的需求。 -
扩展工具调用:通过 ToolCall 机制和角色扮演增强,进一步提升其在 Agents 和复杂任务中的表现。
模型介绍
通过 token 级交错方法实现 Linguistic token 与 Semantic token 的有效整合。Linguistic tokenizer 的码本大小是 1024,码率 16.7Hz;而 Semantic tokenizer 则使用 4096 的大容量码本来捕捉更精细的声学细节,码率 25Hz。鉴于两者的码率差异,建立了 2:3 的时间对齐比例——每两 个Linguistic token 对应三个 Linguistic token 形成时序配对。
语言模型
为了提升 Step-Audio 有效处理语音信息的能力,并实现精准的语音-文本对齐,在 Step-1(一个拥有 1300 亿参数的基于文本的大型语言模型 LLM)的基础上进行了音频持续预训练。
语音解码器
Step-Audio 语音解码器主要是将包含语义和声学信息的离散标记信息转换成连续的语音信号。该解码器架构结合了一个 30 亿参数的语言模型、流匹配模型(flow matching model)和梅尔频谱到波形的声码器(mel-to-wave vocoder)。为优化合成语音的清晰度(intelligibility)和自然度(naturalness),语音解码器采用双码交错训练方法(dual-code interleaving),确保生成过程中语义与声学特征的无缝融合。
实时推理管线
-
语音活动检测(VAD):实时检测用户语音起止 -
流式音频分词器(Streaming Audio Tokenizer):实时音频流处理 -
Step-Audio语言模型与语音解码器:多模态回复生成 -
上下文管理器(Context Manager):动态维护对话历史与状态
后训练细节
在后训练阶段,针对自动语音识别(ASR)与文本转语音(TTS)任务进行了专项监督微调(Supervised Fine-Tuning, SFT)。对于音频输入-文本输出(Audio Question Text Answer, AQTA)任务,采用多样化高质量数据集进行SFT,并采用了基于人类反馈的强化学习(RLHF)以提升响应质量,从而实现对情感表达、语速、方言及韵律的细粒度控制。
模型评测
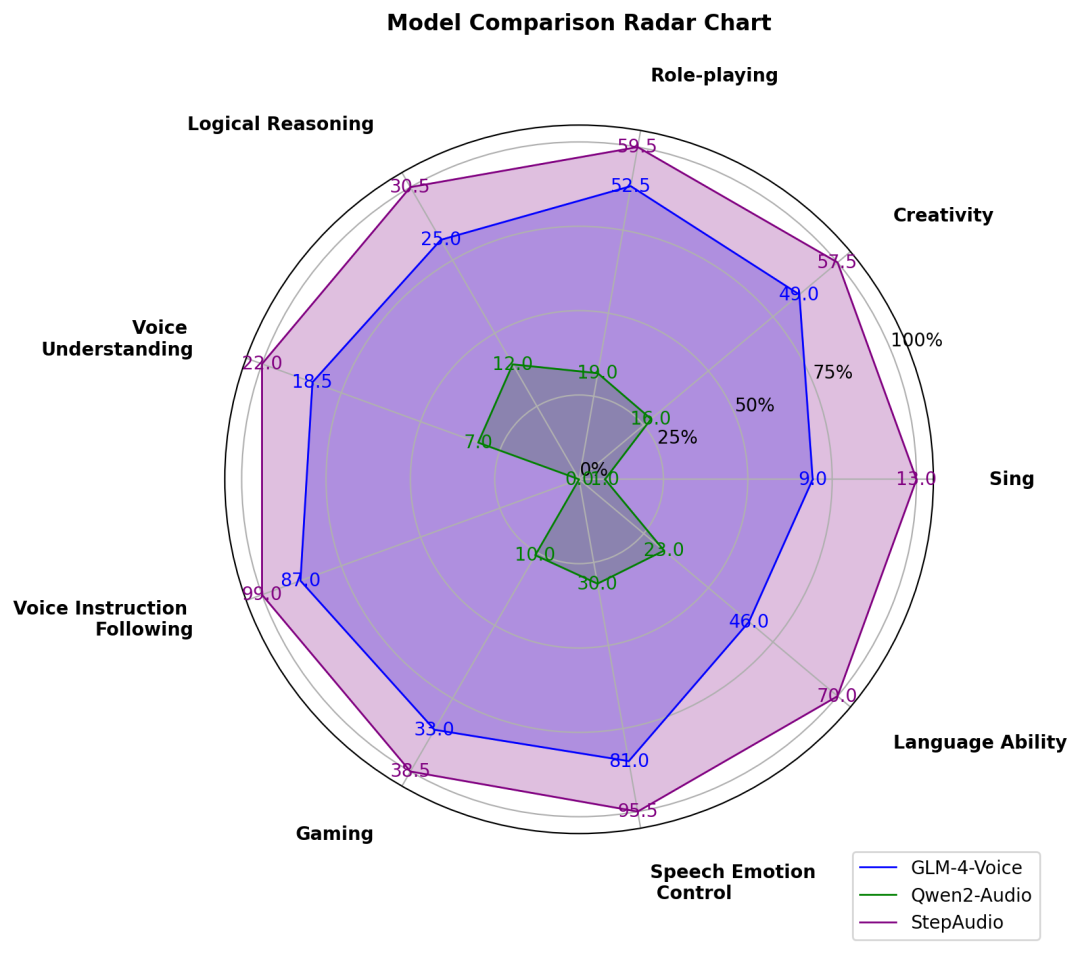
在 LlaMA Question、Web Questions 等 5 大主流公开测试集中,Step-Audio 模型性能均超过了行业内同类型开源模型,位列第一。Step-Audio 在 HSK-6(汉语水平考试六级)评测中的表现尤为突出,是最懂中国话的开源语音交互大模型。
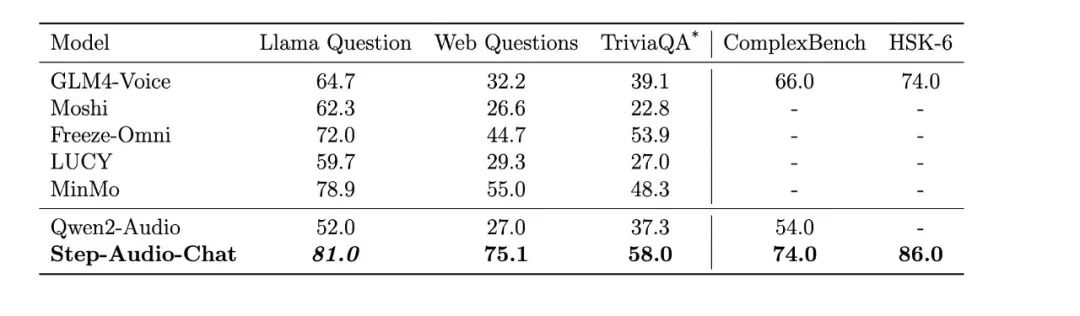 公开评测集评测结果
公开评测集评测结果
比如下面这段对话中,模型能够深入理解中文的博大精深,而不会被「绕晕」。
Step-Audio 也具有高情商的特征,熟知人情世故,当用户面临各种人生问题,它都可以像好朋友一样提供贴心陪伴并帮你出主意。