随着AI技术的迅猛发展,另一个同样火热的赛道也悄然兴起——那就是 AI硬件。什么是AI硬件?简单来说,就是让各种物品“变聪明”。比如,一个普通的小玩偶,如果加上AI硬件,就可以成为孩子的智能老师或陪伴聊天的好朋友;一个杯子加入智能模块,就能定时提醒你喝水、关心你的健康。
在这篇文章中,我们会聊聊AI硬件由哪些部分组成,怎么快速动手实现一个简单的AI硬件系统,并在文末附上手搓的源码地址,方便大家动手实践。
下面是实行运行情况,我们用语音询问AI,AI以四川口音回答我们问题。
要实现一个基本的AI交互设备,我们从最简单的语音问答功能开始:用户说话提问,设备通过网络访问大模型获取答案,然后用语音读出来,并在小屏幕上显示相关信息。
所需硬件清单如下:
-
主控芯片:ESP32 S3,便宜但是性能好的处理器。
-
麦克风(用于录音)
-
功放芯片 + 喇叭(用于播放声音)
-
OLED 显示屏(显示提示信息)

这些硬件在淘宝上总成本不会超过50元,搜索关键词如“小智AI”就能找到现成的套装。

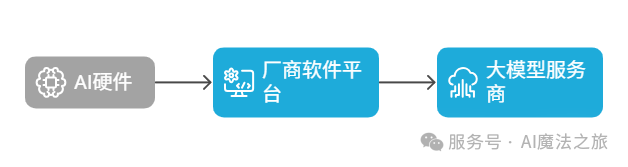
购买后按照卖家的说明把接好,再烧录固件就能使用,非常方便。不过,我们不满足于只用厂商“傻瓜式”的现成方案。厂商的方案是在中间搭一个软件平台,AI硬件先连接到软件平台,再连到大模型服务
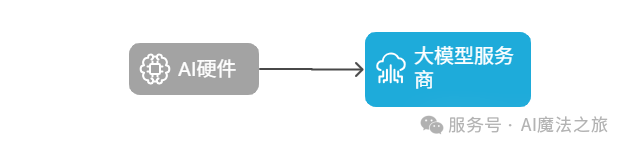
我们希望保持“极客精神”,让我们的AI硬件可以直接对接大模型服务,打造真正属于自己的定制AI设备。
在动手开发之前,先做好这几项软件准备:
1. 刷入 MicroPython 系统
硬件厂商的固件是使用 C 语言开发,开源而且性能优秀,但代码行数多,牵涉的底层知识多,开发门槛较高。相比之下,Python 是AI时代的编程语言,更加轻松易上手,几行代码就能实现复杂功能,非常适合AI项目开发。
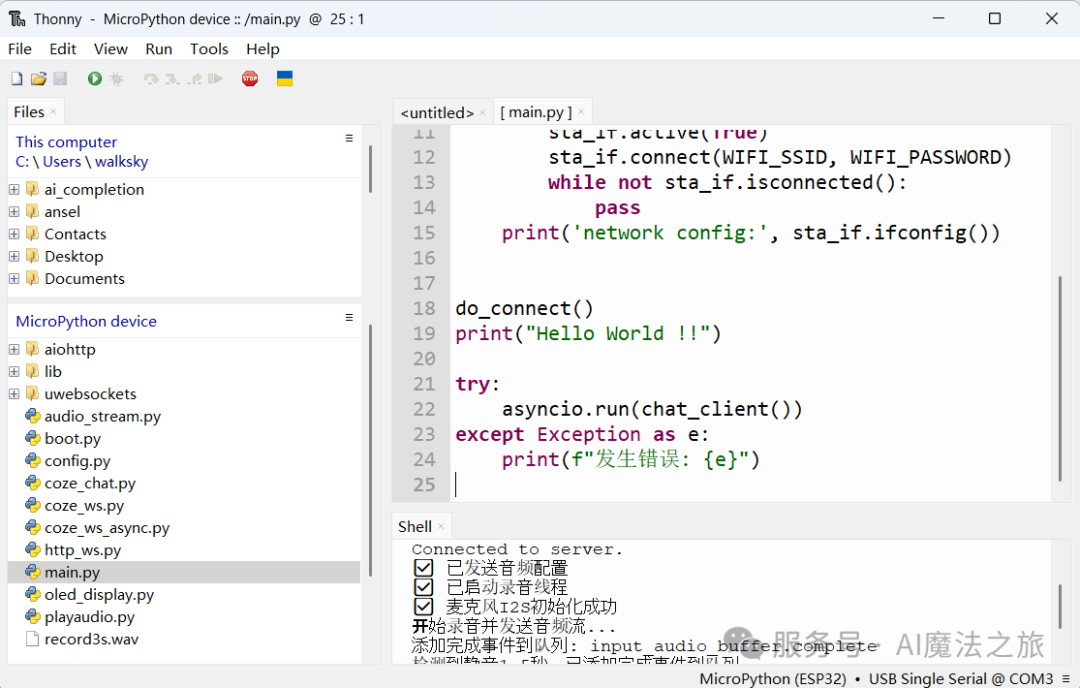
我们先把MicroPython刷到ESP32 之中,这样我们就可以使用Python开发,推荐使用 Thonny IDE ( https://thonny.org/ ),它不仅能刷写固件,还能上传文件、查看调试信息,简单好用。
2.使用Coze 平台智能体
本项目使用 字节Coze 提供的大模型服务,它支持双向语音流式API,还有丰富的语音音色。在开发之前先在coze平台上做三件事
(1) 建立一个智能体, 三分钟就建立完成。
(2) 升级账号到专业版,获取调用语音API权限,先充值3元即可。
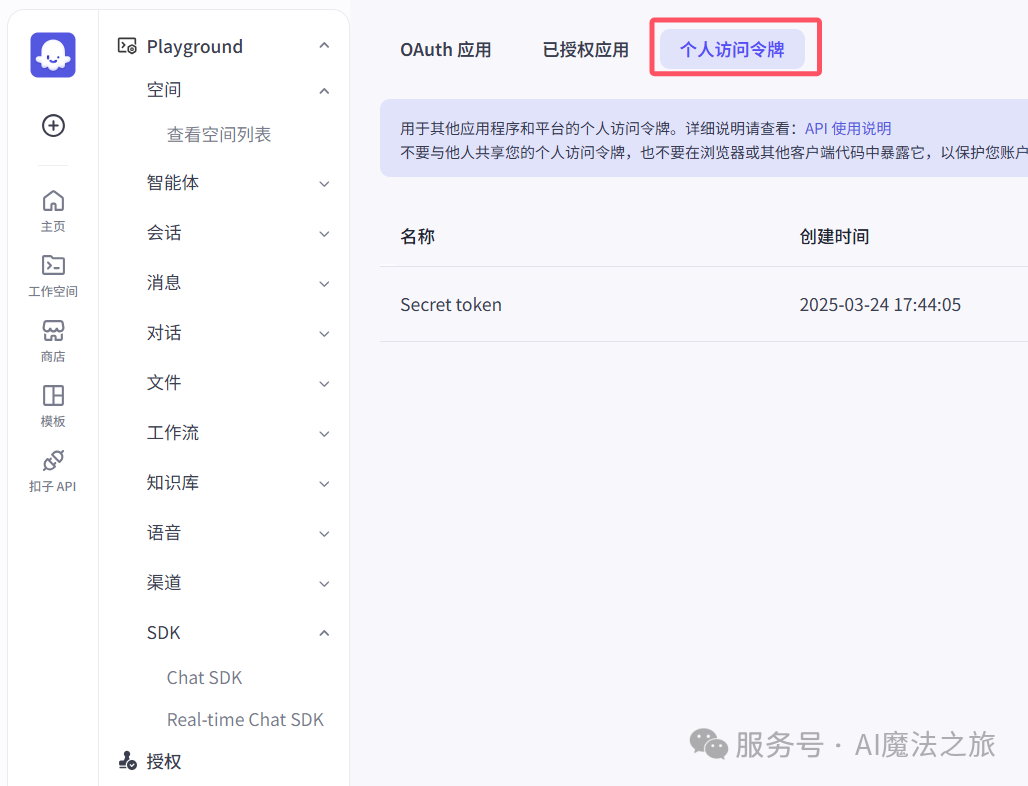
(3) 建立个人访问令牌,用来调用API。
3.借助 AI 帮你写代码
虽然我们用的是Python,但编码工作还是交给AI来写吧。使用同样是字节的TRAE 来作为开发助手,可以有效地节约我们的时间。
接下来我们就正式进入开发阶段,下面简述下开发流程,想直接看代码到这个网址https://github.com/walkskysu/esp32s3_coze
1. 让设备连接上Wi-Fi
ESP32 S3 内建Wi-Fi模块,只需要设置好SSID和密码即可联网。代码简单易懂。
import network
sta_if = network.WLAN(network.STA_IF)
sta_if.active(True)
sta_if.connect(WIFI_SSID, WIFI_PASSWORD)
print('network config:', sta_if.ifconfig())
2. 寻找适合的 WebSocket 库
这是最困难的一关,硬件和大模型服务的通信采用 WebSocket 协议,websocket 具有长连接,同时收发消息的特性,比传统 HTTP 更适合语音流应用。但 MicroPython 并不自带 WebSocket 支持。问遍所有的大模型给出的答案都是指到github一个半成品的库,经过一番摸索,才发现 MicroPython的官方库之中有一个写好的aiohttp_ws 支持 (https://github.com/micropython/micropython-lib/)
3. 改写示例代码
把原先的Python代码让TRAE 使用aiohttp 改写成能在 MicroPython 上运行的版本,完成基本的通讯功能。
请将main.py 中引用的 websocket库改用项目中的aiohttp改写,让main.py可以在ESP32 S3版子上的 micropython 中执行
4. 添加录音功能(I2S)
我们使用 I2S 协议连接麦克风,I2S 是电子设备间传输音频的常用协议。我们告诉TRAE使用I2S录音和发送消息格式,就可以帮我们写好
这个项目是在ESP32 S3的micropython上执行, 在发送音频配置后,启动I2S的录音thread , 持续发送音频流到服务端,格式为{
"id": "event_id",
"event_type": "input_audio_buffer.append",
"data": {
"delta": "base64EncodedAudioDelta"
}}
5. 加入静音检测
为了知道用户是否说完问题,我们加入静音检测功能:持续1.5秒内无声音,就判断为“提问完成”,然后进入回答阶段。
代码增加静音检测,在说一段话后,静音1.5秒后,发送{
"id": "event_id",
"event_type": "input_audio_buffer.complete"
},再接着录音发送信息
6. 播放AI语音回答
把大模型返回的音频数据,通过 I2S 推送到功放芯片,实现语音播放。
这个项目是在ESP32 S3的micropython上执行,在执行过程会收音频数据,格式如下
{"id": "event_id",
"event_type": "conversation.audio.delta",
"data": {
"content": "base64EncodedAudioDelta"
}
}
请解码后送到I2S播放
7. 增加显示功能
用 OLED 显示屏提示当前状态,比如“聆听中”、“回答中”等。但要注意,嵌入式系统中没有字体库,我们需要用这个网站 https://www.zhetao.com/fontarray.html 生成点阵字体
这个项目是在ESP32 S3的micropython上执行 ,参考 oled_display.py ,在录音时,oled显示listen_words,在播放声音时显示talk_words
在整个开发过程,我们是透过和TRAE 对话交互的方式进行,虽然它可以帮我们写代码,但是测试、debug和提解决方案还是要自己来。未来AI编程取代工程师还是有很远的路。
本文介绍了所需的硬件设备与软件准备过程,并一步步搭建出一个可语音交互的智能设备,涵盖了联网、WebSocket通信、音频录制与播放、静音检测及OLED显示等关键功能。我们坚持极客精神,不依赖中间平台,直接对接大模型服务,打造了一个完全自主可控的AI系统。附上的源码https://github.com/walkskysu/esp32s3_coze 可以直接使用或改造
AI魔法之旅频道提供专业的AI信息和专业评测,如果觉得文章不错,请记得点赞、收藏、转发三连
往期精彩文章:
-
AI 编程革命:用 AI 实现 10 倍速开发
-
本地部署DeepSeek-R1,低成本实现强大推理
-
用AI打造佛学大师-零基础AI训练数据集制作指南
-
《黑神话:悟空》全球玩家口碑分析
-
零基础也能搞定!快速搭建本地大型语言模型指南
-
AI对话升级 - 画图、解读图像、上网查资料
-
在微信上免费使用AI对话