过去一段时间我们见证了AI 硬件的加速进化——从智能眼镜到智能体耳机,各大科技公司都在探索AI 与硬件融合的新形态。智能眼镜承载了无感信息获取与记录的愿景,智能耳机则主打智能助手随时在线的概念
然而,在 AI 语音交互领域,还存在一个关键痛点:如何提供价格低廉、稳定、持续在线的 AI 体验?智能眼镜和耳机的 AI 交互仍受限于功耗、计算性能和使用环境等约束,很难提供长时间、独立手机外的深入对话。因此给智能语音聊天盒子留出空间
相比智能耳机、智能眼镜,智能聊天盒子不受续航和硬件形态的限制,可以更稳定地运行本地 TTS(文本转语音)、ASR(语音识别),并结合大模型进行深度 AI 交互。它不仅可以充当私人 AI 助理,还能拓展到家庭、办公场景,成为你的“AI 桌面伴侣”
那么,这类智能聊天盒子是如何制作的?我将从硬件选型和软件核心体验两方面来展开解析
硬件
去年 OpenAI 发布一个支持 ESP32 的 Realtime API SDK 后彻底带火了乐鑫的 ESP32 的芯片,导致现在语音聊天盒子的方案绝大部分都是用 ESP32-S3 的

ESP32-S3 支持了 Wi-Fi 和 BLE,内置 AI 指令集,且价格低廉,淘宝上卖 39 元,但算力有限,本地难以运行 LLM,需要走云端推理。麦克风和扬声器需要外接,当然也可以根据产品的定位考虑加屏幕,加视觉摄像头了,需要具体看想解决什么问题

但加的越多,交互模态越丰富,对于产品的定位,及用户的预期等都会做出更高的要求,且工程的挑战也会越大,这里需要不断地问,加屏幕是用来解决什么问题?加摄像头是用来解决什么问题?......而且加越多会发现和手机的形态越像,这也是之前分析其它智能硬件时一个逃不开的话题

ESP32-S3面包板方案外接了扬声器、麦克风和显示屏
目前网上有用 ESP32-S3 做的各种硬件形态,外壳很多是 3D 打印的,最新的形态有加上躯体的、有做成儿童陪伴机器的,又或者是做成手表形态的
当然,除了 ESP32-S3 外,也有其他的芯片方案,像 ASR8601C 等都可供选择,有些直接带了 4G 通信,可以打随身陪伴的概念
软件
目前,智能聊天盒子的软件方案主要分为两类:有屏幕版(带触控屏 GUI 的 AI 设备)和无屏幕版(纯语音交互的智能音箱形态)。有屏幕的设备可以提供更丰富的 UI 交互。无屏幕设备则更强调“无感交互”的理念,但在复杂任务处理上存在一定局限
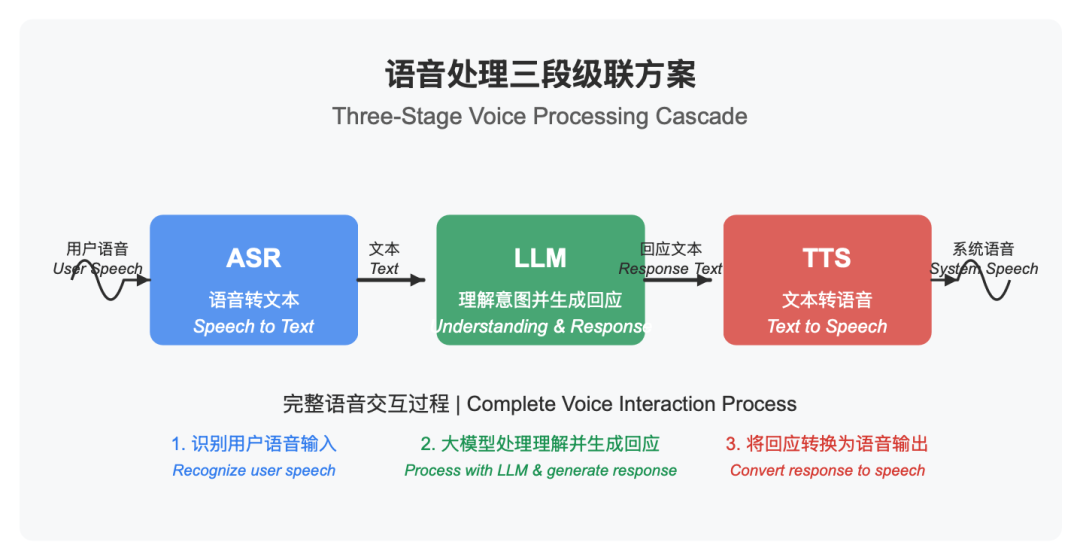
-
ASR(Automatic Speech Recognition)——语音转文本 -
LLM(大模型推理)——理解用户意图并生成回应 -
TTS(Text-to-Speech)——文本转语音
相比之下,实时语音大模型方案(直接从语音输入到语音输出,无需文字中间层)正在成为新趋势。优点是交互更加流畅,减少 ASR、TTS 的损耗,情感表达也更到位;缺点是对算力和模型优化要求高,token 费用贵,且时延也会更高,目前仍处于探索阶段
这个是我年前手搓的简易聊天对话盒子的方案,ASR、TTS、LLM 全部用成熟公司的开放平台接口,跟着开源方案实现的
另外,加屏幕的话需要重新设计一套 GUI ,目前市场上带屏幕方案的 GUI 设计都是不合格的,更多只是用来玩玩。如果是设计一些带卡通或机器人外形的智能设备,屏幕往往还要充当眼镜及情感的表达,又会涉及表情 AIGC、情感引擎等技术,如蔚来汽车的 NOMI

NOMI 的部分表情,可结合摄像头、语音等对表情交互
另外,语音聊天盒子加摄像头的话就增加了视觉模态,可以结合语音去做多模态,比如:“帮我看下这个是什么?”、“翻译下当前的文字”、“朗读下当前的内容”等等,这又会拓展出很多使用场景
可以预见智能聊天盒子后面会结合 Agent ,充分发挥 LLM+ Agent 的能力,有更强的任务执行能力,真正成为“随时待命的 AI 伙伴”,而不仅仅是一个高级语音助手
最后
这一波大模型的高速发展,我们即将迎来智能硬件的寒武纪大爆发,这是一个新时代。如果你对这些感兴趣,有些想法想交流,欢迎后台联系我~