今天的 Voice Agent 学习笔记,分享来自锦秋基金的语音 AI 深度报告。报告指出 2B 和 2C 赛道值得关注的方向:
2B 领域:
-
垂直语音客服;
-
企业工作流 Agent;
-
培训/招聘模拟;
-
自动化 AI 语音智能体测试。
2C 领域:
-
AI 教育:儿童在线解题与陪伴学习到成人语言教学,均快速演进。
-
陪伴/心理疗愈:陪伴 AI 距离《Her》式体验仍需时日,心理疗愈核心挑战是合规与避免幻觉。
-
语音驱动 AI 游戏:短期 AI 陪玩难替真人,但语音驱动游戏(如 Volley)拓宽商业空间。
-
智能硬件 AI Agent:短期聚焦随身智能体体验,长期看好 AR/VR 等沉浸式硬件拓展交互。
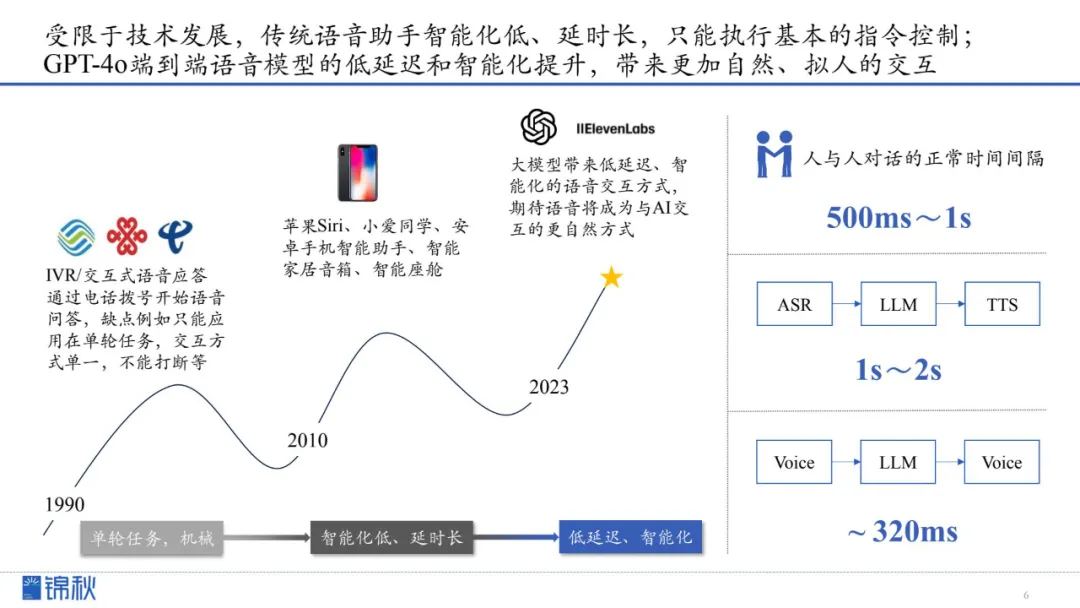
自从通信诞生之初,语音就一直是人类最自然的交流方式,而当大模型(LLM)推动AI朝向更“聪明”、“拟人”的方向前进时,语音交互正成为下一代智能体验的核心接口。相比文本,语音不仅能承载语调、情绪、音色和呼吸节奏等丰富信息,还能以极低的操作门槛帮助儿童、老人等群体更轻松地接入AI服务,进而拓宽AI应用的用户群与使用场景。
尽管早期的语音交互(如IVR或初代智能助手)在智能化、响应速度和多轮对话灵活性上受限,但近年随着GPT-4o这类模型的崛起,延迟已从原先的1~2秒降至320毫秒级别,接近人类对话的自然节奏。
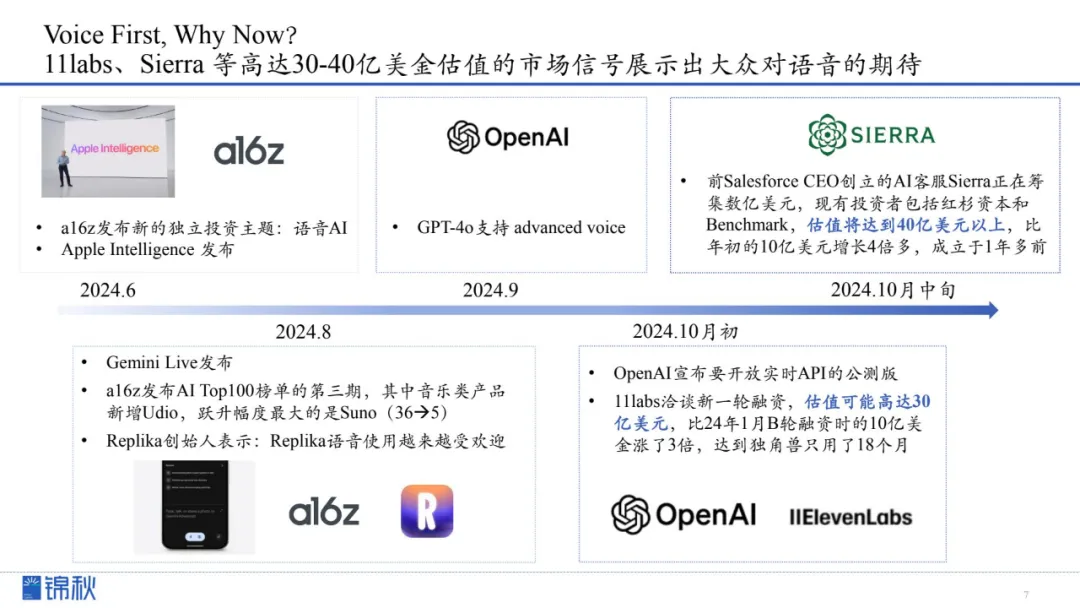
新工具不但实现了情感化表达和真假难辨的语音生成,还能在娱乐、生产力和情感陪护等领域展现出更高的价值。这一转变也得到了市场热捧,包括Sierra、11labs在内的初创企业在短短数月内融资估值倍增,证明语音交互技术被视为下一个潜力巨大的增长点。
如今,随着OpenAI宣布开放实时API公测、a16z和Replika等投资与产品方持续押注,语音AI正全速走向成熟。人类无需再透过冰冷的键盘和搜索框与机器交流,真正的自然化、低门槛、情感融入的交互体验已在眼前。AI语音时代的到来,不仅为技术赋予了温度,更为大众的日常生活与商业应用开启了全新的想象空间。
-
语音不再只是辅助手段,在LLM驱动下,它正逼近人类的自然交流极限,从延迟、情感到上下文理解全面迭代,成为下一代智能交互的关键入口。
-
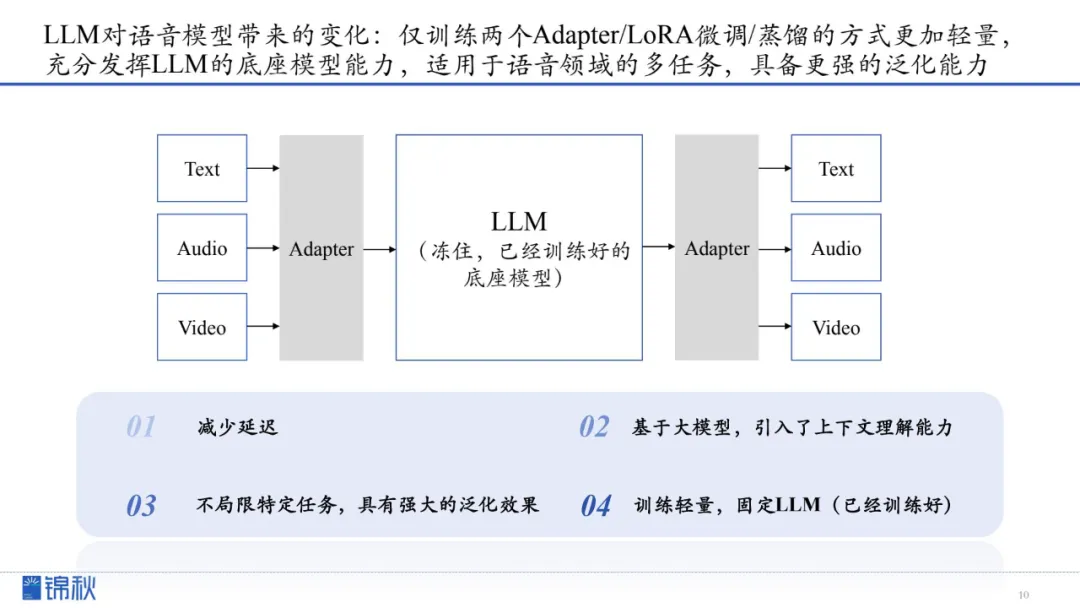
LLM对语音模型的冲击核心在于“冻住大模型+轻微训练”的新范式,让ASR、TTS一举跨入轻量、泛化、多任务支撑的新时代。
-
在ASR层面,大模型打通从音频编码器到语言模型的端到端通路,识别准确率接近天花板,但专有领域、口音、多人对话等复杂边缘场景依旧顽固难啃。
-
TTS从依赖人工设计特征转向语音离散化表征,大数据与LLM让生成层次激增,不仅零样本泛化可期,还能更灵活控制情感、语速与音色。
-
端到端模型表面华丽,但在企业级(2B)落地时,却绕不开“可控性、准确度、低延迟”的不可能三角,RAG与模块化方案依旧有其坚固阵地。
-
大厂在端到端与通用场景上虽有先发优势,但被监管、成本和可控性限制;创业公司在TTS定制化、价格与数据飞轮方面反而更可能穿透市场。
-
2C市场仍在孵化:教育、陪伴、AI游戏、智能硬件等潜力尚未定型,价值虽高,但短期商业化仍不清晰,下一个真正声学原生的杀手级应用仍在等待萌芽。
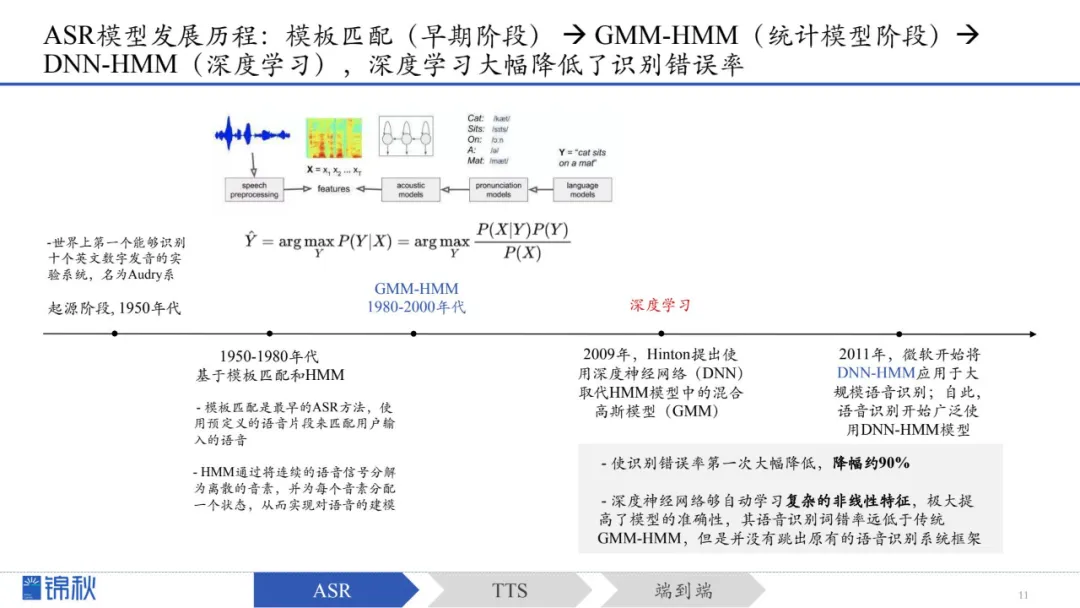
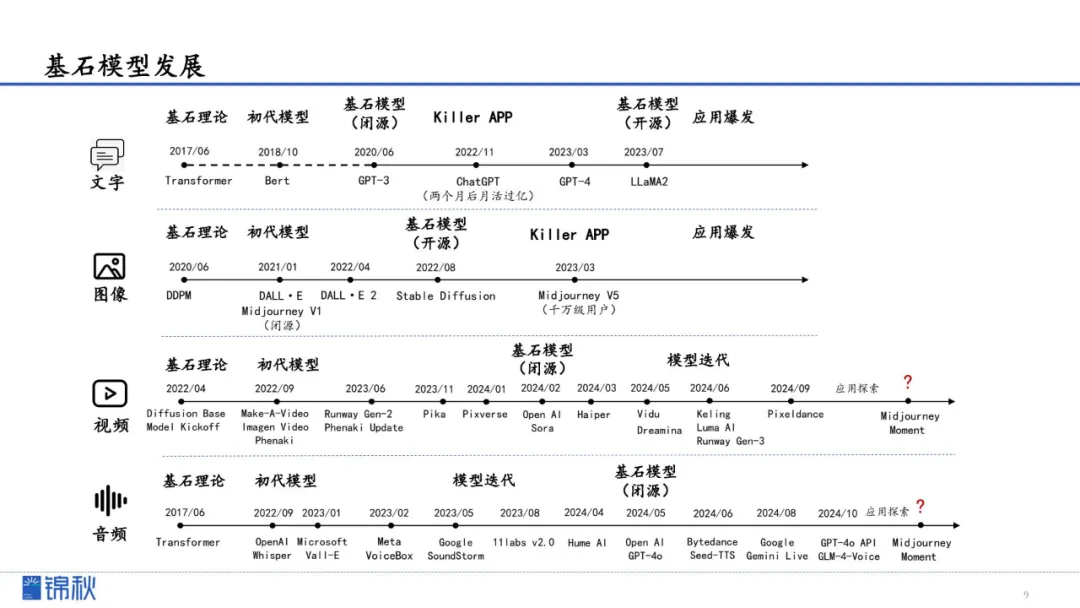
文字、图像和视频模态的大模型都已经有了各自开源或是闭源的基石模型,音频的基石模型可能相对较晚。从80年代至今,语音领域的发展共有两条主线。
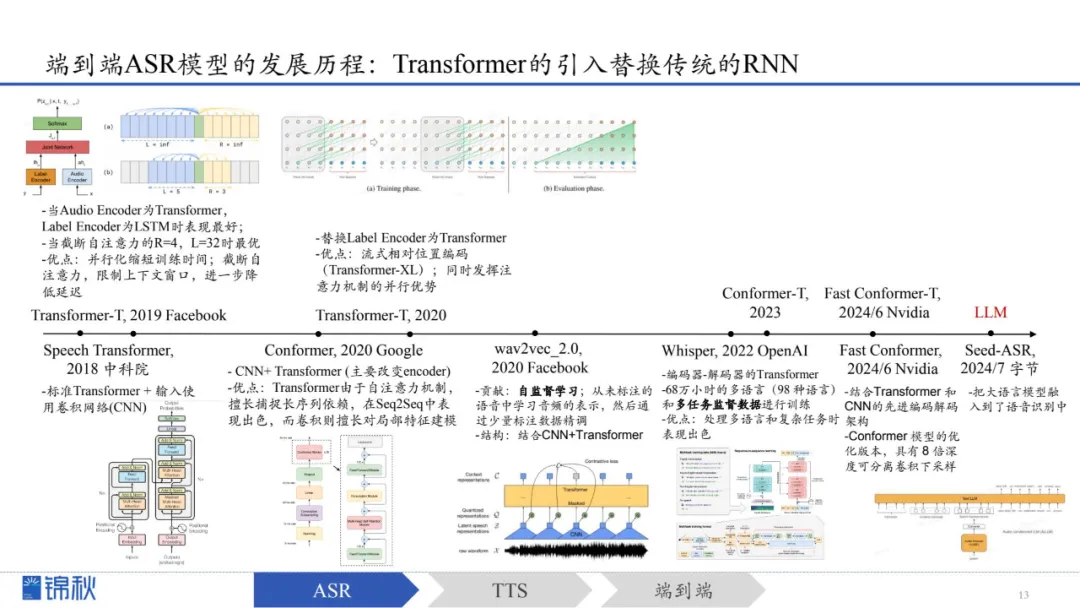
第一条主线:早期的ASR和TTS经历了统计模型阶段、深度学习时代,直到2017年引入Transformer,后来逐步进入LLM时代
第二条主线:从ASR、TTS等单个模型的迭代,三级联模式逐步发展到以GPT-4o为代表的端到端模型
 仅训练Adapter/LoRA微调/蒸馏的方式更加轻量,充分发挥LLM的底座模型能力,适用于语音领域的多任务,具备更强的泛化能力。
接下来将具体阐述ASR、TTS和端到端的发展,以及LLM对这些模型带来的影响。
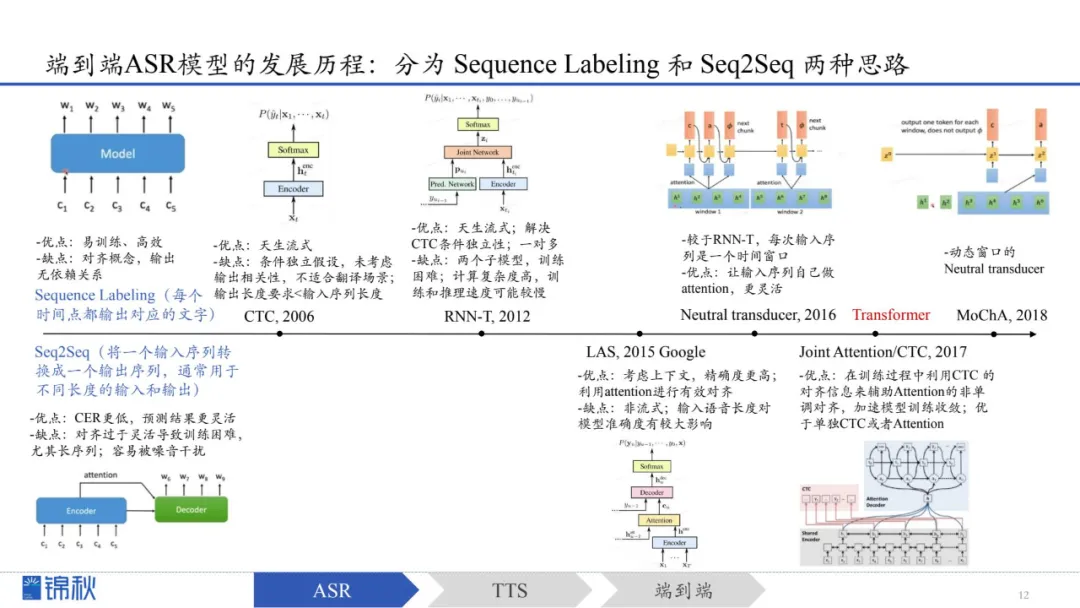
随后出现端到端ASR模型,可直接从语音频谱到文本输出,简化训练
一类(Sequence Labeling)训练和推理较为简单高效,但上下文理解能力较弱;
另一类(Seq2Seq)输出更灵活、识别更准确,但训练和对齐较复杂。后来通过融合方案(如加入CTC对齐机制)在一定程度上同时兼顾了效率与灵活性,使训练和性能更为稳定。
进入Transformer时代的端到端ASR模型通过超大规模数据和自监督预训练,大幅减少对标注数据的依赖,并提升多语种、多任务的处理能力。以Whisper为例,它利用海量数据实现了出色的多语言识别和复杂任务处理能力。
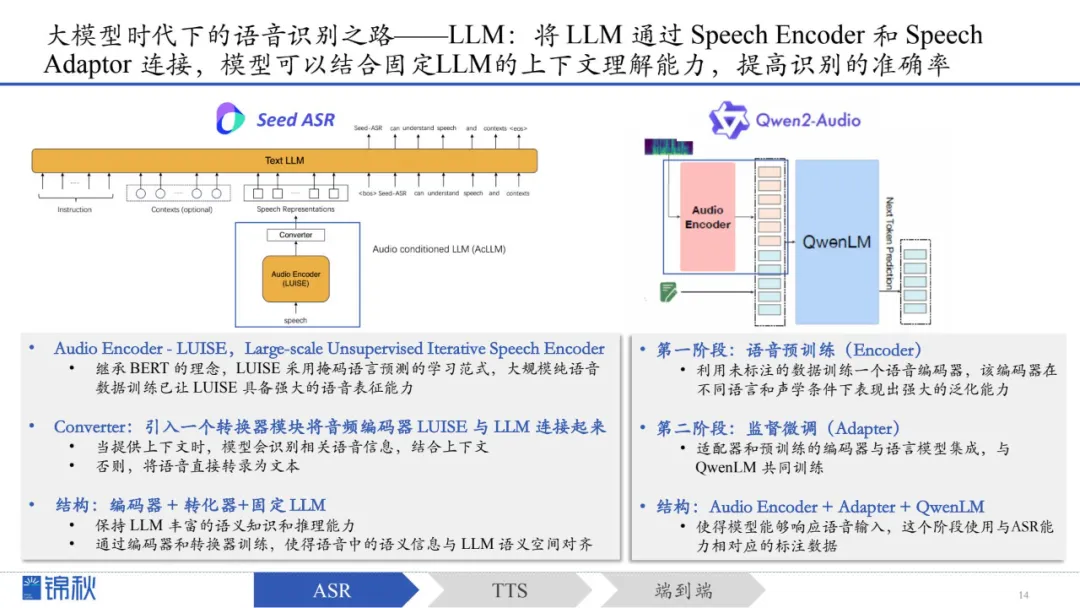
大模型时代下的语音识别之路——LLM:核心思想是将 LLM 通过 Speech Encoder 和 Speech Adaptor 连接,模型可以结合固定LLM的上下文理解能力,提高识别的准确率。此处以Seed-ASR和Qwen2-Audio为例:
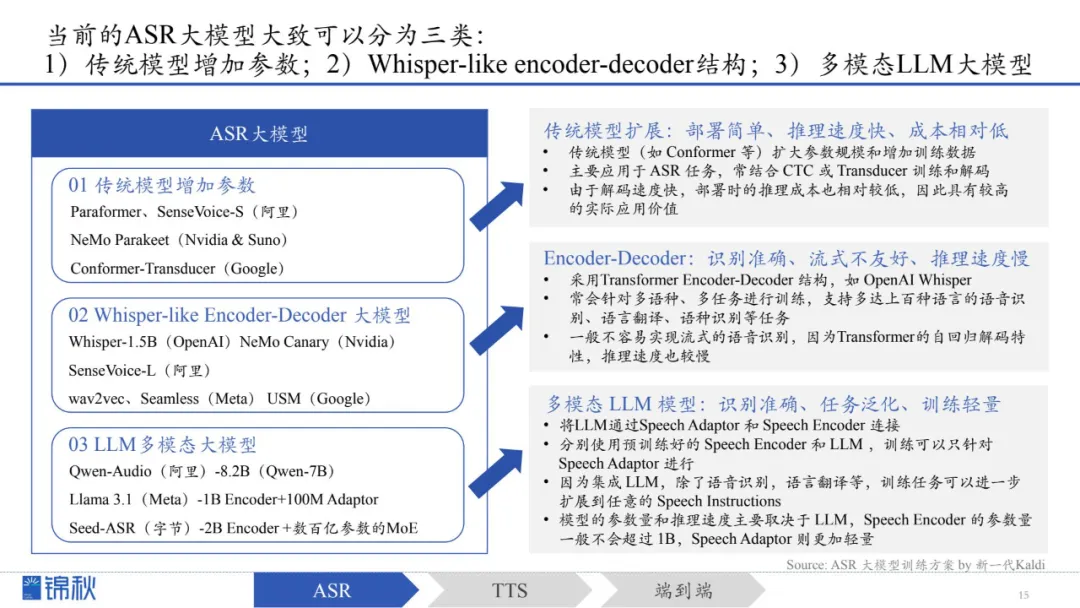
1.传统模型增加参数:Sequence Labeling路线,部署简单、推理速度快、成本相对低
2.Encoder-decoder结构:Seq2Seq路线,识别准确、流式不友好、推理速度慢
3.多模态LLM大模型:识别准确、任务泛化、训练轻量
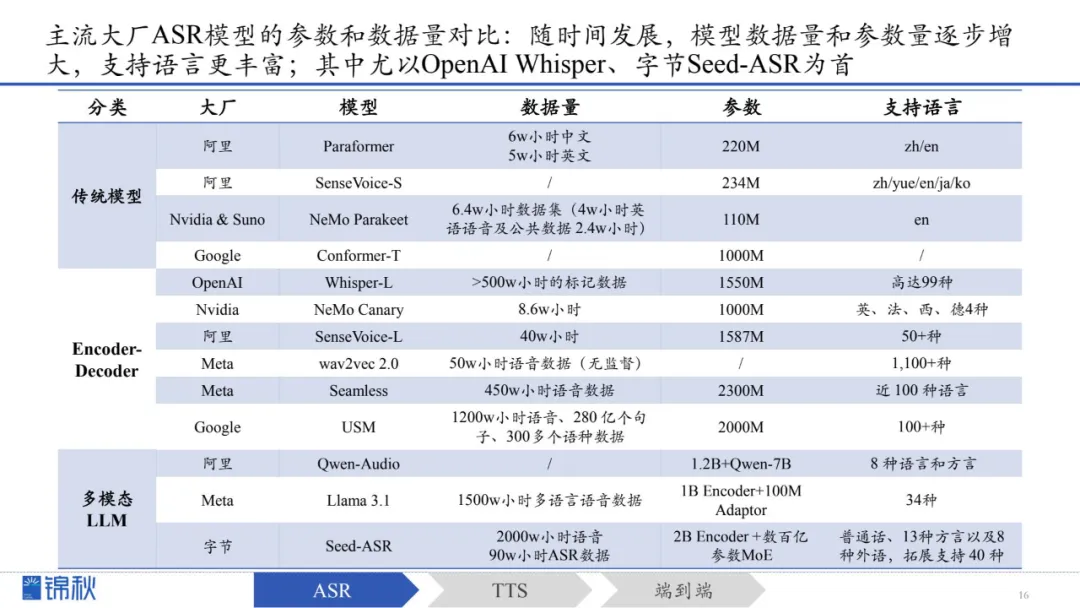
通过对比主流大厂ASR模型的参数和数据量,不难发现随时间的发展,从传统模型-->Encoder-Decoder模型-->多模态LLM:
1.模型数据量和参数量逐步增大,从早期Whisper的68万小时数据量,到Seed-ASR采用2000万小时的语音数据和90万小时的ASR数据进行训练;
2.支持语言也更加丰富,从简单中英文拓展至多种外语,甚至支持方言。
仅训练Adapter/LoRA微调/蒸馏的方式更加轻量,充分发挥LLM的底座模型能力,适用于语音领域的多任务,具备更强的泛化能力。
接下来将具体阐述ASR、TTS和端到端的发展,以及LLM对这些模型带来的影响。
随后出现端到端ASR模型,可直接从语音频谱到文本输出,简化训练
一类(Sequence Labeling)训练和推理较为简单高效,但上下文理解能力较弱;
另一类(Seq2Seq)输出更灵活、识别更准确,但训练和对齐较复杂。后来通过融合方案(如加入CTC对齐机制)在一定程度上同时兼顾了效率与灵活性,使训练和性能更为稳定。
进入Transformer时代的端到端ASR模型通过超大规模数据和自监督预训练,大幅减少对标注数据的依赖,并提升多语种、多任务的处理能力。以Whisper为例,它利用海量数据实现了出色的多语言识别和复杂任务处理能力。
大模型时代下的语音识别之路——LLM:核心思想是将 LLM 通过 Speech Encoder 和 Speech Adaptor 连接,模型可以结合固定LLM的上下文理解能力,提高识别的准确率。此处以Seed-ASR和Qwen2-Audio为例:
1.传统模型增加参数:Sequence Labeling路线,部署简单、推理速度快、成本相对低
2.Encoder-decoder结构:Seq2Seq路线,识别准确、流式不友好、推理速度慢
3.多模态LLM大模型:识别准确、任务泛化、训练轻量
通过对比主流大厂ASR模型的参数和数据量,不难发现随时间的发展,从传统模型-->Encoder-Decoder模型-->多模态LLM:
1.模型数据量和参数量逐步增大,从早期Whisper的68万小时数据量,到Seed-ASR采用2000万小时的语音数据和90万小时的ASR数据进行训练;
2.支持语言也更加丰富,从简单中英文拓展至多种外语,甚至支持方言。
GMM-HMM / DNN-HMM
Sequence Labeling 和 Seq2Seq
Speech-encoder-adapter-LLM
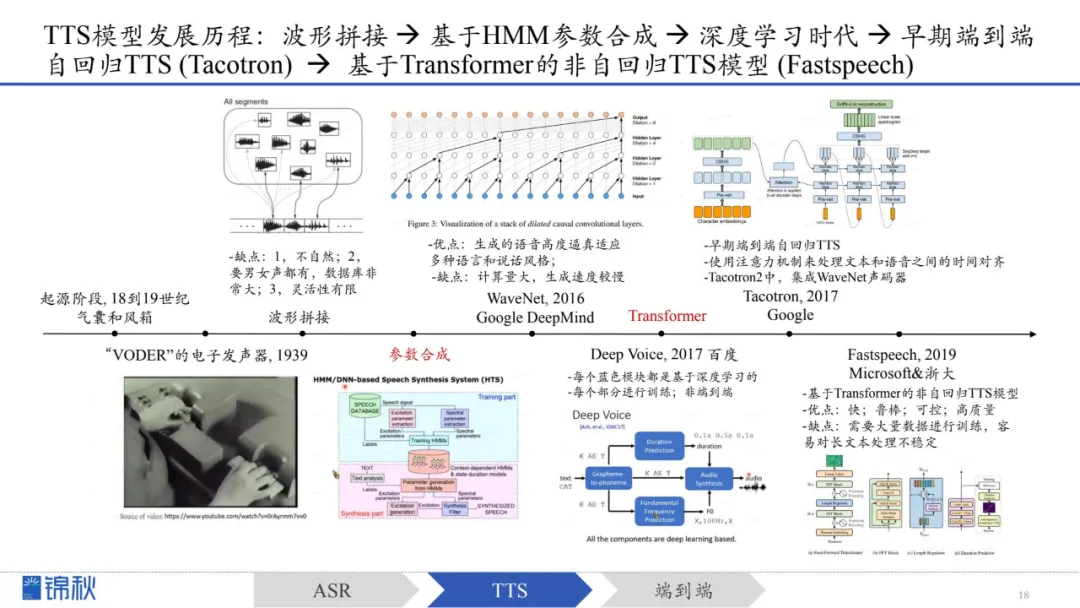
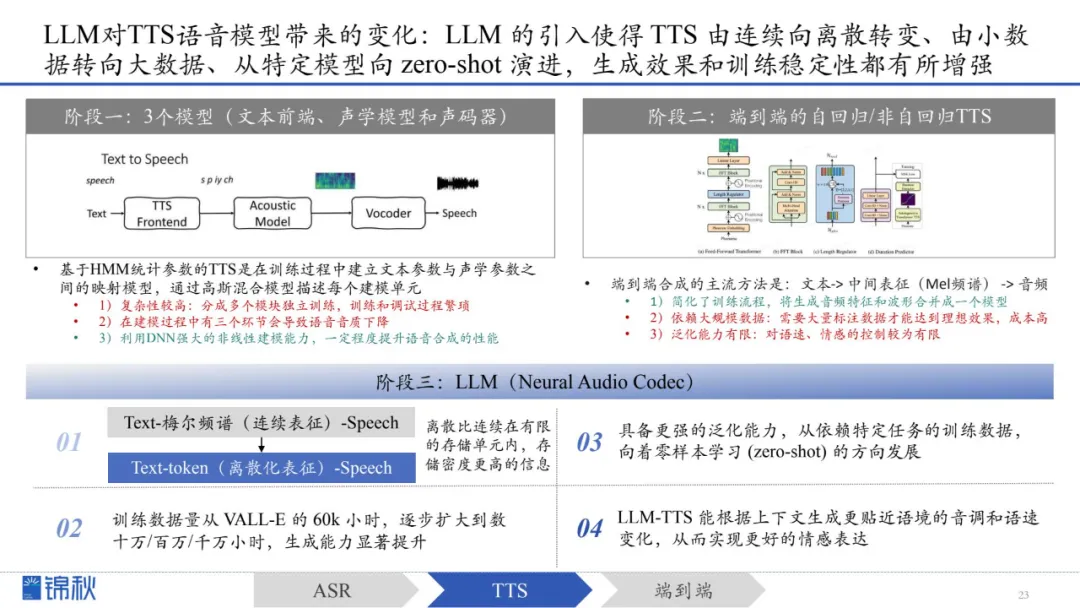
从最早利用机械与电子装置模拟发声,到利用拼接与参数化方法,再进入深度学习时代,实现从文本到音频的一体化端到端合成,语音合成的自然度和灵活性不断提升。
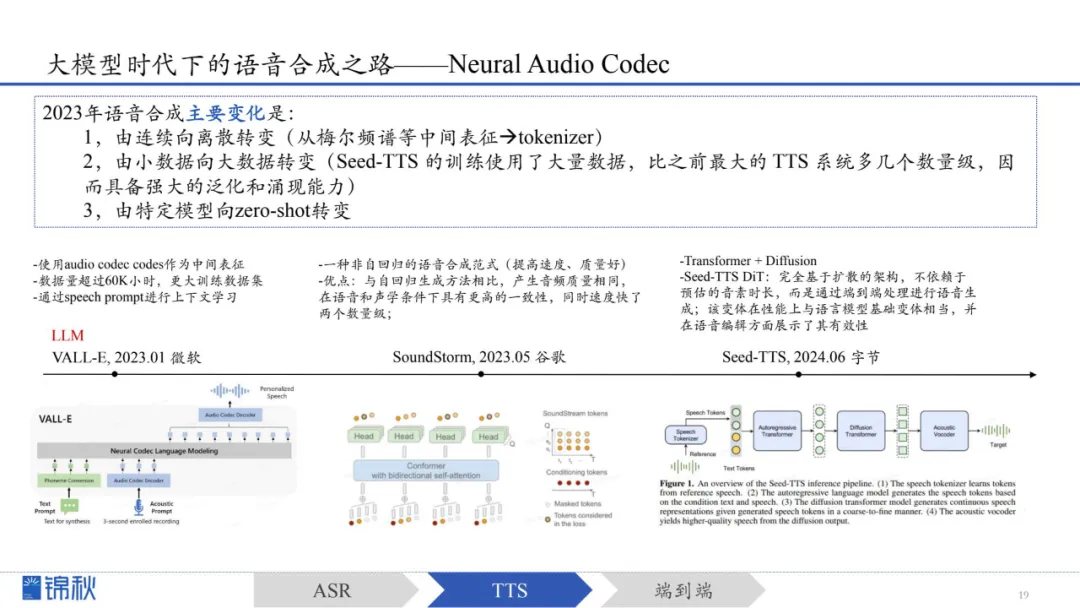
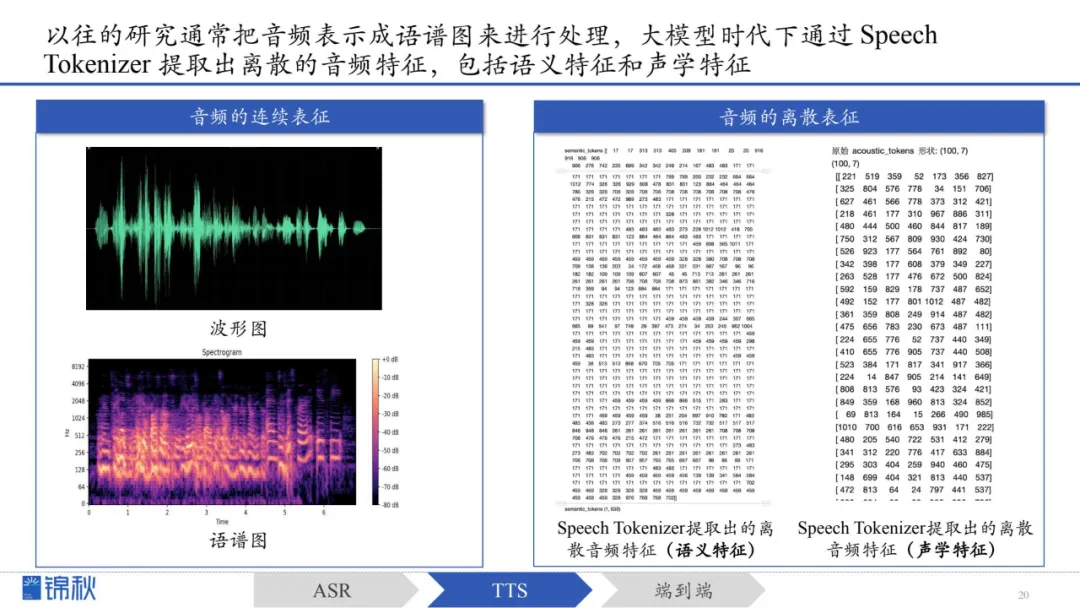
大模型时代,语音合成从过去依靠人工设计的特征(如梅尔频谱)转向采用“离散化语音表示”。相比传统特征,离散表示使训练过程更稳定、可利用预训练方法提升性能,并将原本的复杂预测转化为更简单的分类问题。
这一变化在2023年开始显著体现:从连续到离散、从小数据到大数据、从特定任务到可零样本适配的通用模型。其中,如VALL-E这类采用神经网络音频编码器(Neural Audio Codec)的模型,为TTS带来了更强的泛化能力与灵活性。
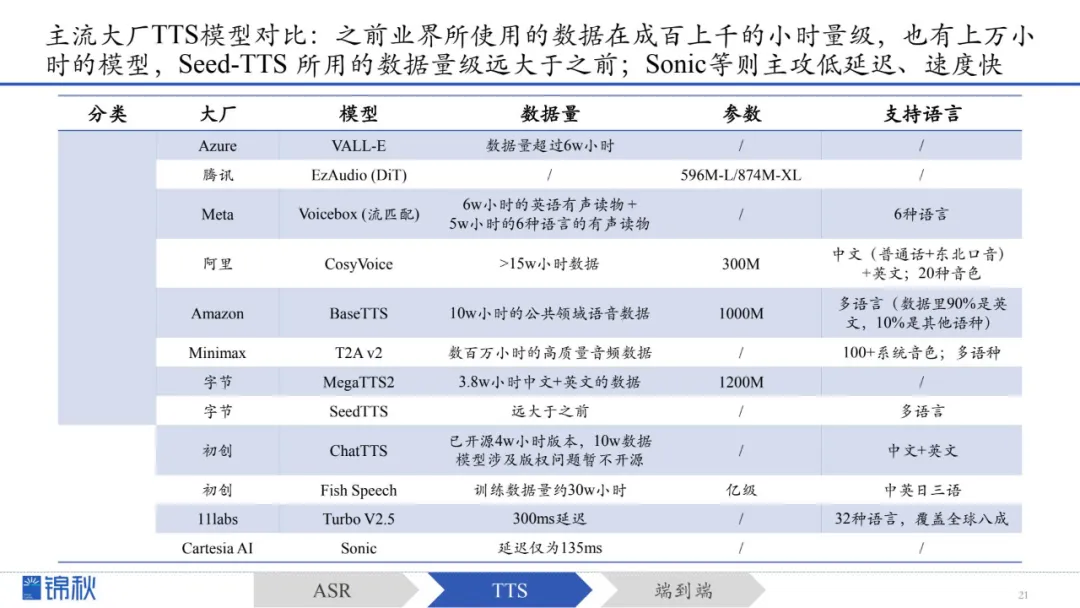
通过对比主流大厂TTS模型的参数和数据量,不难发现:
1.之前业界所使用的数据在成百上千的小时量级,也有上万小时的模型,特别是VALL-E的数据量超过6万小时(当时是一个很大的突破),而Seed-TTS 所用的数据量级远大于之前;实际上,TTS公开可用的数据量远低于ASR数据。
2.语音合成,要么专攻准确性、效果好,拼数据量,要么攻低延迟,例如初创Cartesia推出的Sonic,延迟仅为135ms,远低于11labs的Turbo V2.5模型的300ms延迟。
阶段一:3个模型(文本前端、声学模型和声码器)
阶段二:端到端的自回归/非自回归TTS
阶段三:LLM(Neural Audio Codec)
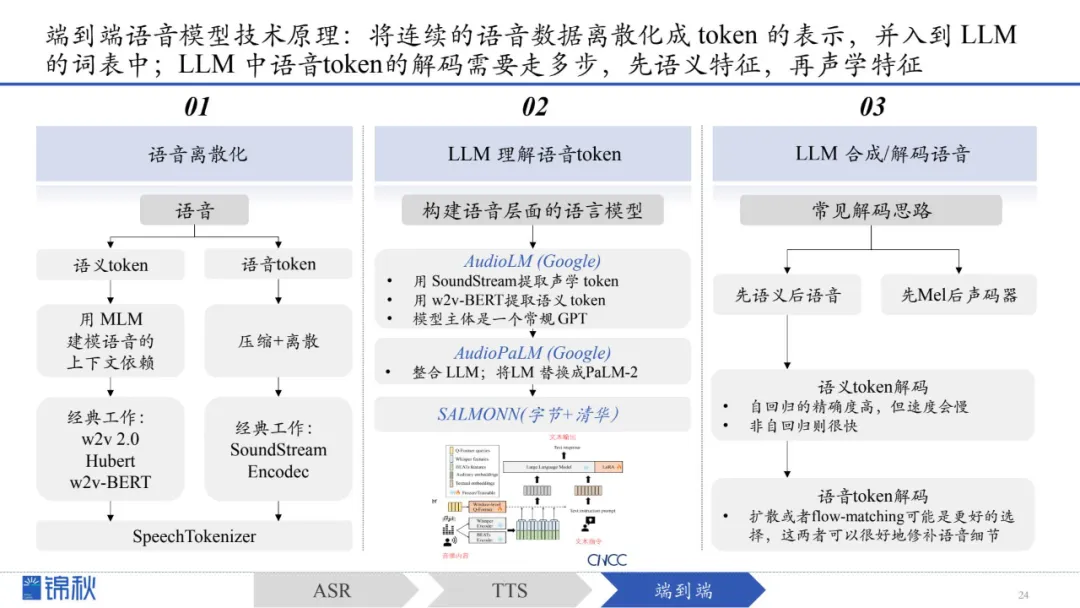
将前述基于LLM的ASR和TTS语音模型相结合,便构成了端到端语音模型基本的技术原理
第一步,语音离散化
第二步,构建语音层面的LLM模型
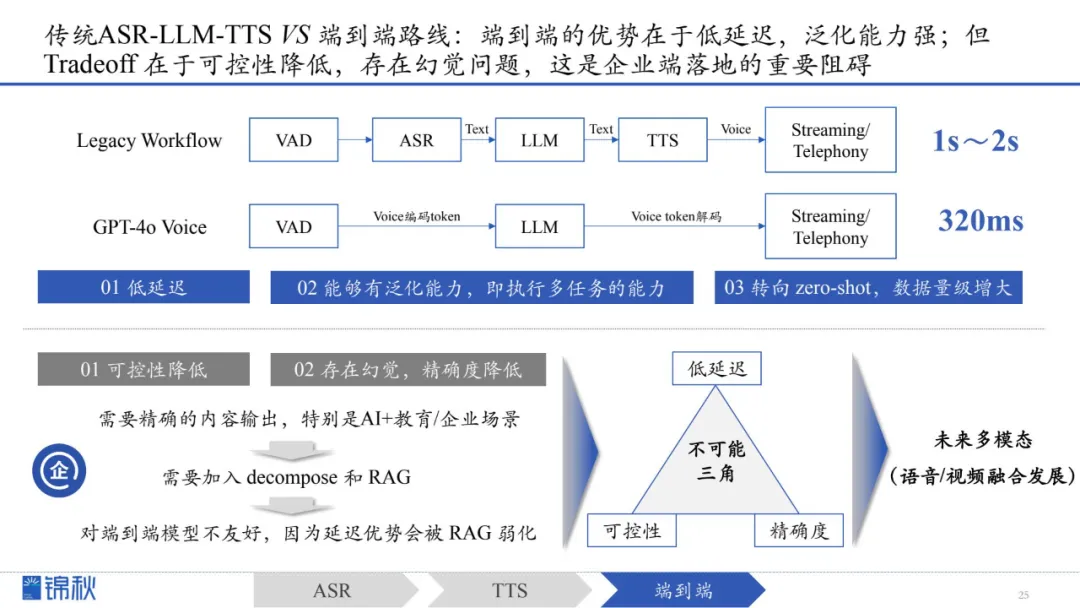
尽管端到端模型显著降低了延迟,泛化能力强,但同时也降低了可控性,存在幻觉问题,这是企业端落地的重要阻碍;企业在使用时需要精确的内容输出,特别是AI+教育/企业的场景,此时就需要 decompose 和 RAG 的加入,但这对端到端模型并不友好,因为其延迟优势会被 RAG 弱化,此时可控性、精确度和低延迟成为不可能三角。
从长远看,多模态融合是发展的确定性趋势,目前端到端语音模型作为新思路,仍处于比较初期的阶段,期待通过数据集的不断优化和扩大,解决模型的幻觉问题
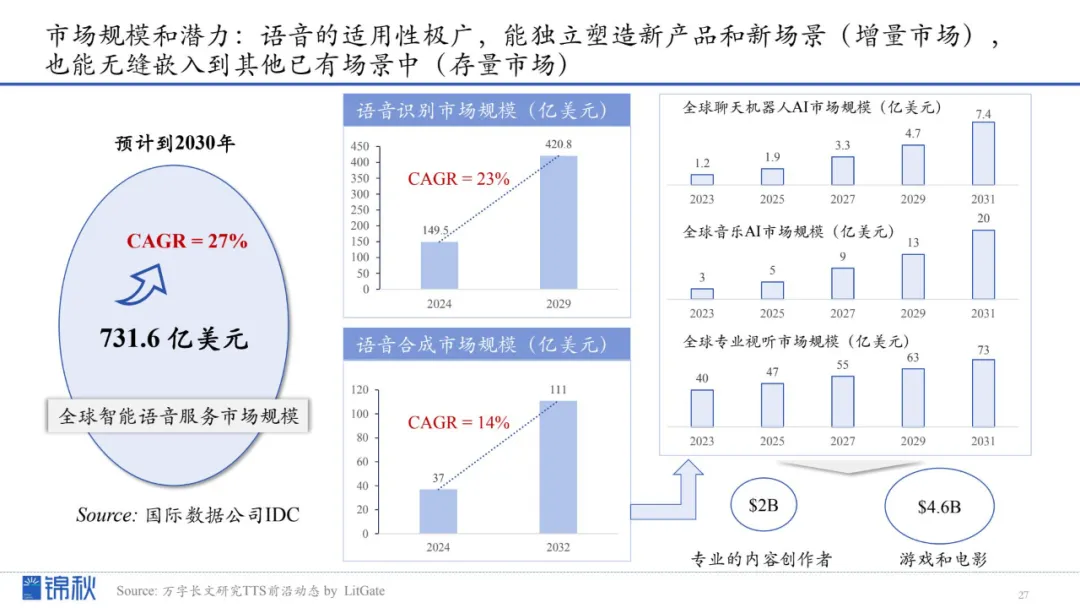
IDC预计,到2030年全球智能语音服务市场规模将达731.6亿美元(年复合增长率约27%)。在传统语音识别(至2029年达420.8亿美元,CAGR 23%)和语音合成(111亿美元,CAGR 14%)市场稳步扩张的同时,聊天机器人、音乐AI及专业视听服务等新兴领域也在不断催生新机遇。
-
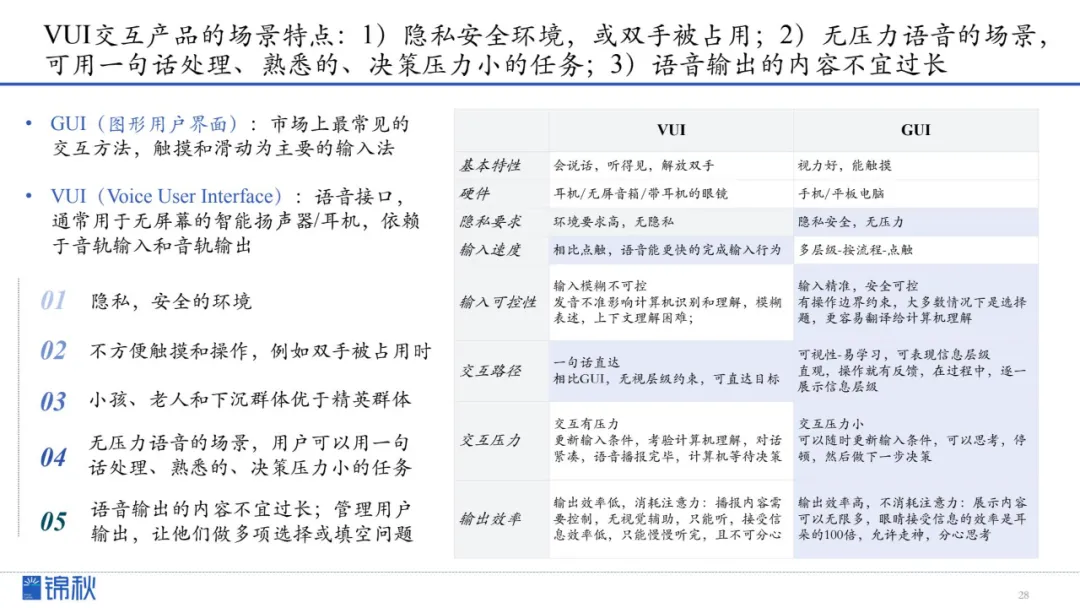
VUI(Voice User Interface) vs. GUI(Graphic User Interface)交互特性对比
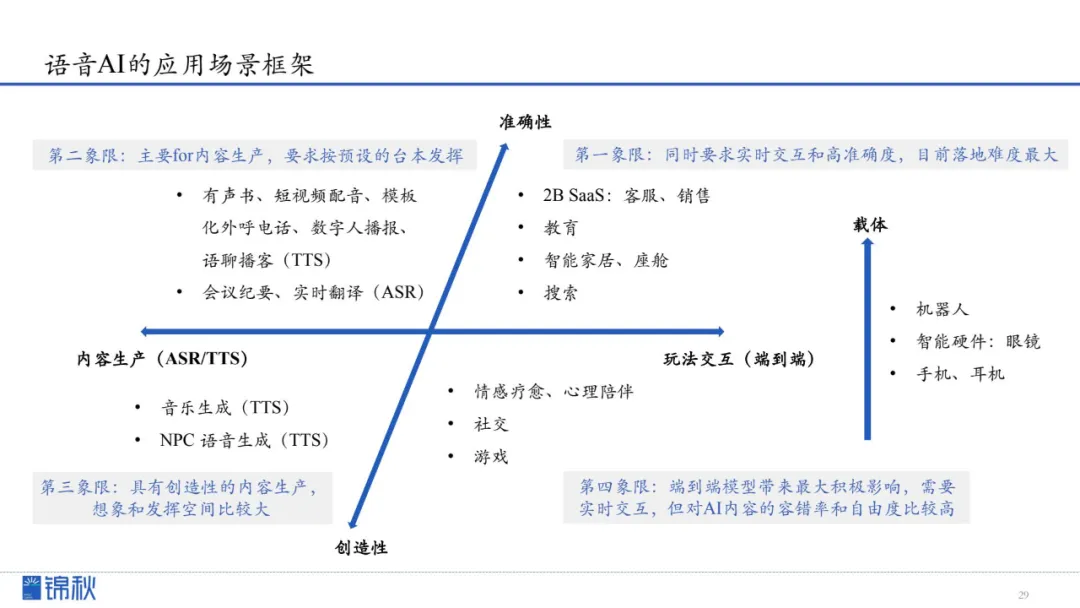
我们将语音AI的应用场景分为两大维度:一是使用场景,分为内容生产和玩法交互两个方向;二是自由度,强调模型应该注重准确性还是创造性。
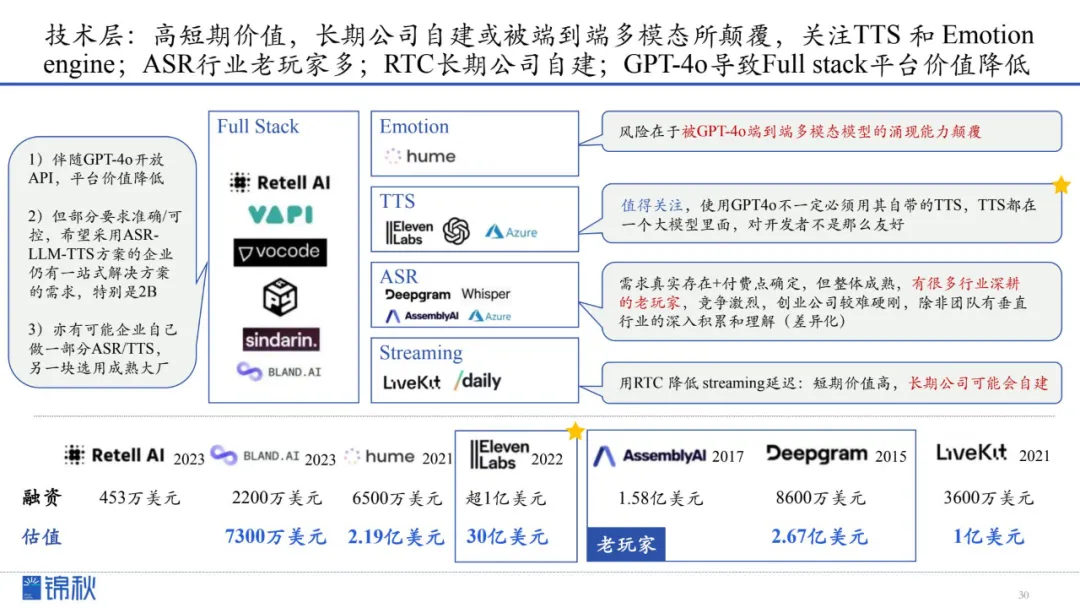
1.高短期价值,长期公司自建或被端到端多模态所颠覆,关注TTS 和 Emotion engine;ASR行业老玩家多;RTC长期公司自建;GPT4o导致Full stack平台价值降低
2.端到端大概率被科技大厂垄断,创业公司在TTS单点模型仍有机会;11labs的先发优势拉动数据飞轮,核心亮点包括定制化、数据飞轮优势、价格便宜
技术API 正在向 ASR/TTS 产品形态转变,整体呈现以下特征:
-
技术趋于成熟,商业化价值潜力大。
-
ASR(自动语音识别)领域更多聚焦垂直场景的转录产品。
-
TTS(文本转语音)则主要关注数字人配音、NPC配音、短视频配音(VTS)以及音乐生成等应用。
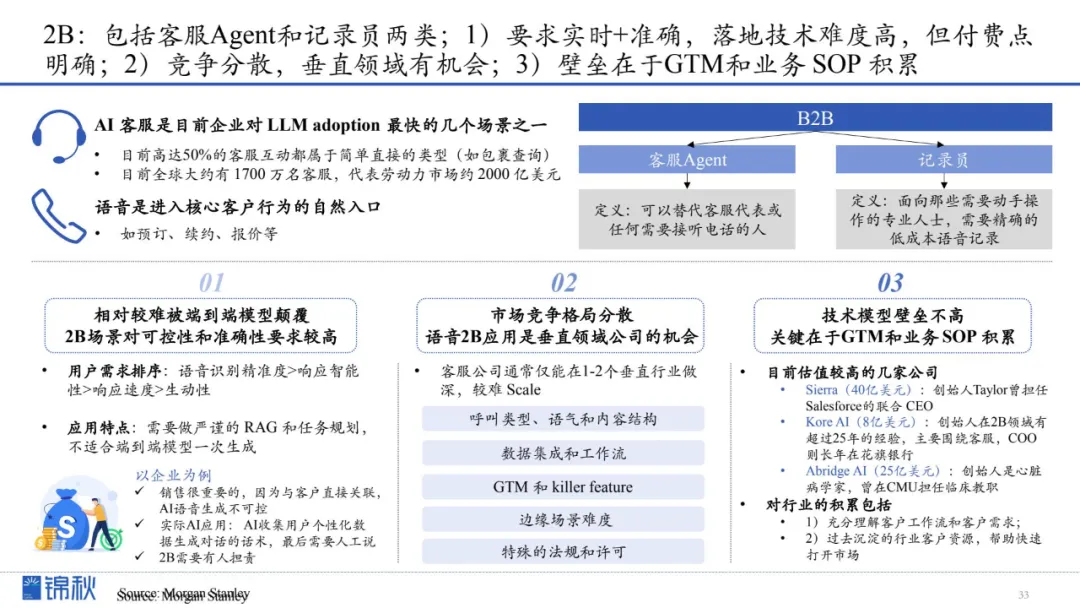
1.2B相对较难被端到端模型颠覆,对可控性和准确性要求较高
2.市场竞争格局分散,语音 2B 应用是垂直领域公司的机会
3.技术模型壁垒并不高,关键在于 GTM 和业务 SOP 的积累
1.垂直赛道的语音客服;
2.企业工作流领域的Agent;
3.培训/招聘模拟;
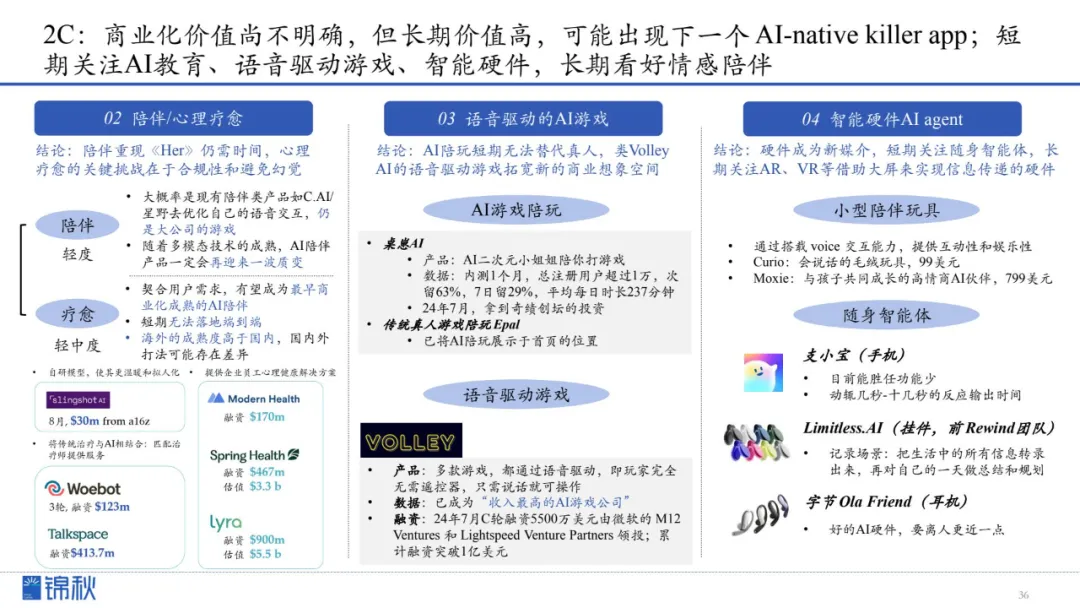
2C领域的商业化价值仍不明朗,但长期价值潜力巨大。在未来,我们或许会看到下一个真正原生于AI时代的“杀手级”应用诞生。短期内可重点关注AI教育、语音驱动的游戏以及智能硬件领域;长期来看,情感陪伴类服务也有望成为重要趋势。
在引入实时交互后,AI教育正逐渐适应更加多元化的学习场景,从儿童在线解题与陪伴学习到成人语言教学,均呈现出快速演进的趋势。
结论:陪伴AI距离《Her》式体验仍需时间,心理疗愈的核心挑战是合规与避免幻觉。
结论:短期内AI陪玩难替代真人,但语音驱动游戏(如Volley)拓宽商业空间。
未来,智能硬件成为信息传播新媒介。短期聚焦随身智能体体验,长期看好AR/VR等更沉浸式硬件拓展交互空间。
RTE 开发者社区持续关注 Voice Agent 和语音驱动的下一代人机交互界面。如果你对此也有浓厚兴趣,也期待和更多开发者交流(每个月都有线上/线下 meetup,以及学习笔记分享),欢迎加入我们的社区微信群,一同探索人和 AI 的实时互动新范式。
加入我们:加微信 Creators2022,备注身份和来意(公司/项目+职位+加群),备注完整者优先加群。
更多 Voice Agent 学习笔记:
Gemini 2.0 来了,这些 Voice Agent 开发者早已开始探索……
帮助用户与 AI 实时练习口语,Speak 为何能估值 10 亿美元?丨Voice Agent 学习笔记
市场规模超 60 亿美元,语音如何改变对话式 AI?
2024 语音模型前沿研究整理,Voice Agent 开发者必读
从开发者工具转型 AI 呼叫中心,这家 Voice Agent 公司已服务 100+客户
WebRTC 创建者刚加入了 OpenAI,他是如何思考语音 AI 的未来?
人类级别语音 AI 路线图丨 Voice Agent 学习笔记
语音 AI 革命:未来,消费者更可能倾向于与 AI 沟通,而非人工客服
语音 AI 迎来爆发期,也仍然隐藏着被低估的机会丨 RTE2024 音频技术和 Voice AI 专场
下一代 AI 陪伴 | 平等关系、长久记忆与情境共享 | 播客《编码人声》
Voice-first,闭关做一款语音产品的思考|社区来稿