图片来源于网络
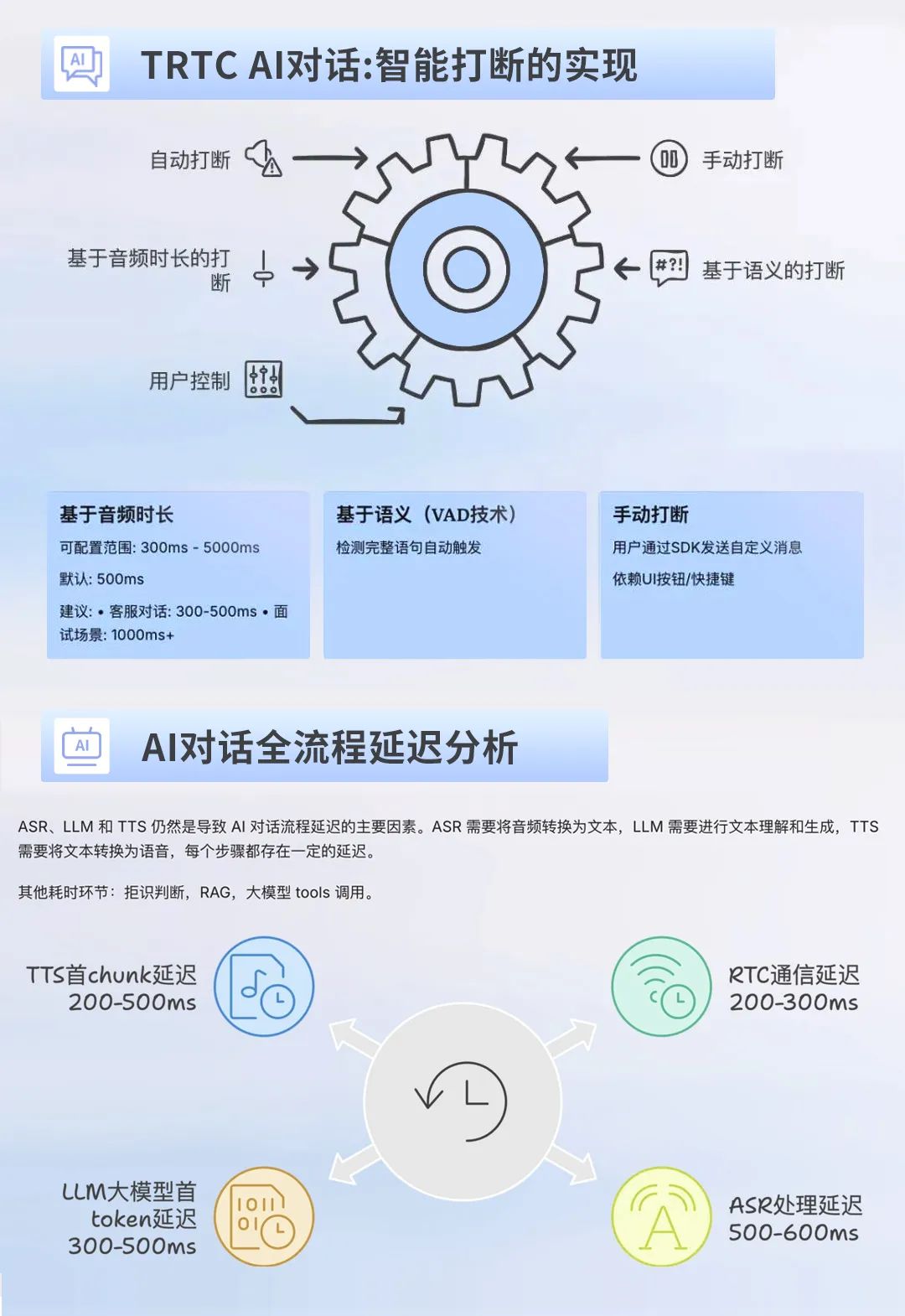
最近整理了新接触的几个关于AI语音识别的方案。几个发展趋势值得大家关注,一是深度学习技术的广泛应用,提升识别准确性,二是对端到端系统简化,提升低延迟及高效率,而多语言和方言支持及应用将会逐渐成为标配。
1.Moonshine:
https://github.com/usefulsensors/moonshine
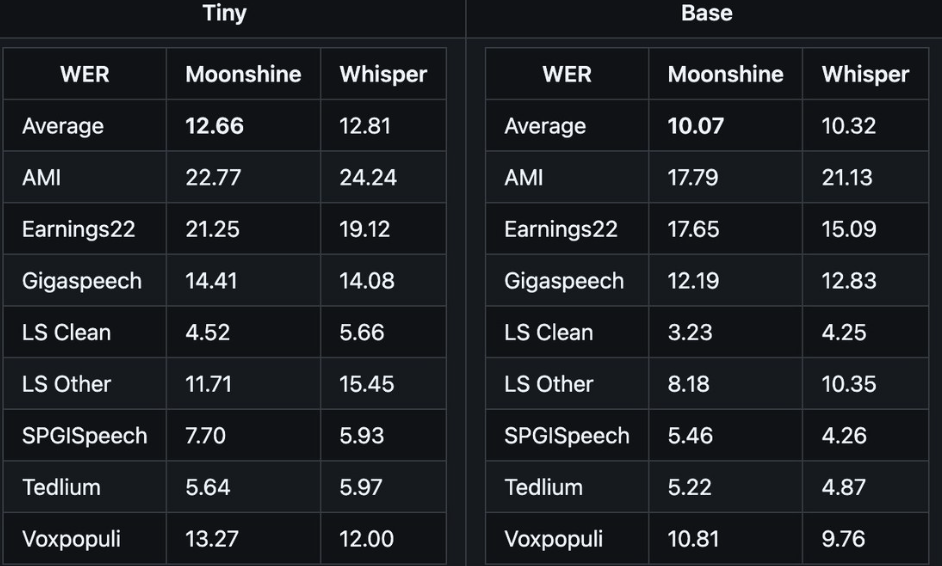
颠覆性实时语音识别,低延迟高准确,在10秒音频剪辑上,速度比Whisper快5倍,同时能保持与Whisper相同的准确性,可以说完胜!
支持可变长度的输入,它可以根据实际语音内容动态调整处理的数据量,不是像Whisper那样固定处理30秒的音频块,处理短音频速度显著提升。
同时在多个标准数据集上,Moonshine 展现出比Whisper模型更低的词错误率。
这种效率性非常适合在资源受限的设备上进行实时语音识别任务。
2. MaskGCT
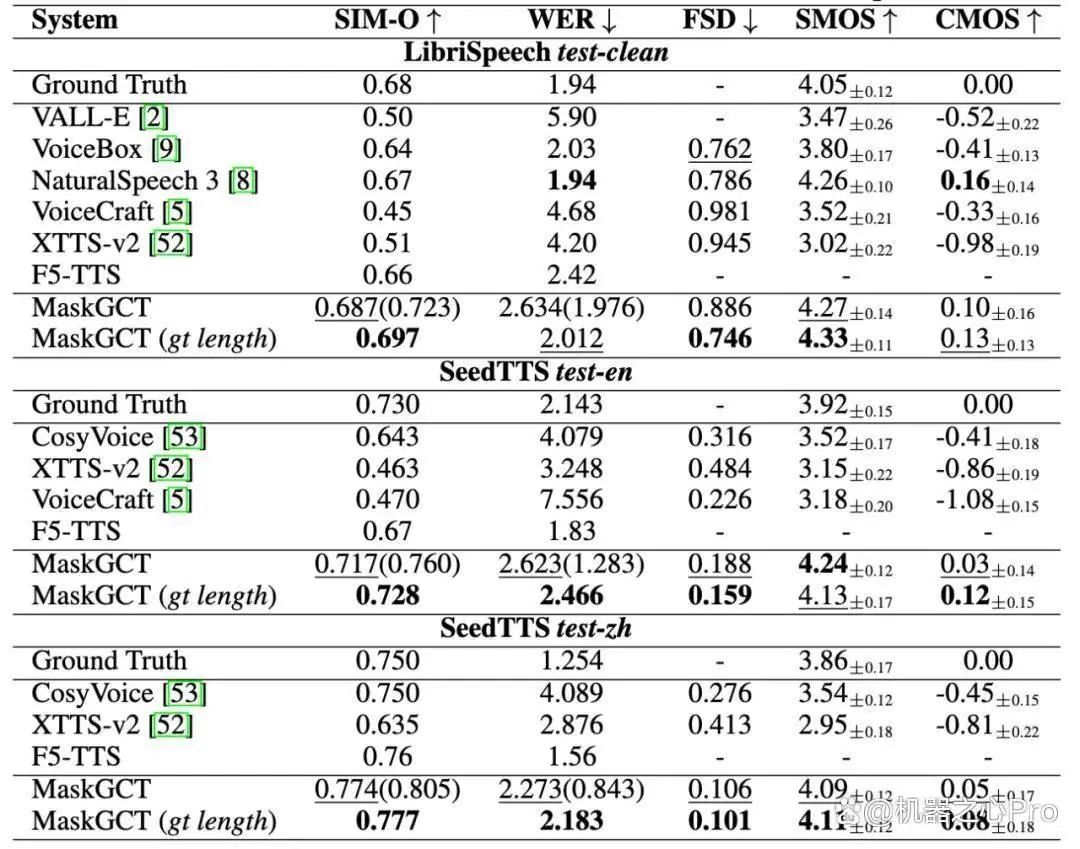
国产最强语音大模型MaskGCT最近宣布开源,声音效果媲美人类,它不需要文本和语音之间的显式对齐信息,也不需要音素级别的持续时间预测,采用了掩码和预测的学习方式,在声音克隆、跨语种合成、语音控制等方面表现优秀
 图片来源于网络
图片来源于网络
1、支持控制生成语音的总长度,可调节语速、停顿等韵律特征、支持情感控制和语气调整,比如开心的、悲伤的、生气的、平静的等情绪,完全克隆人类。
2、支持零样本语音合成,可以修改已生成的语音,支持声音转换和克隆
github:
https://github.com/open-mmlab/Amphion/tree/main/models/tts/maskgct…
项目:https://maskgct.github.io
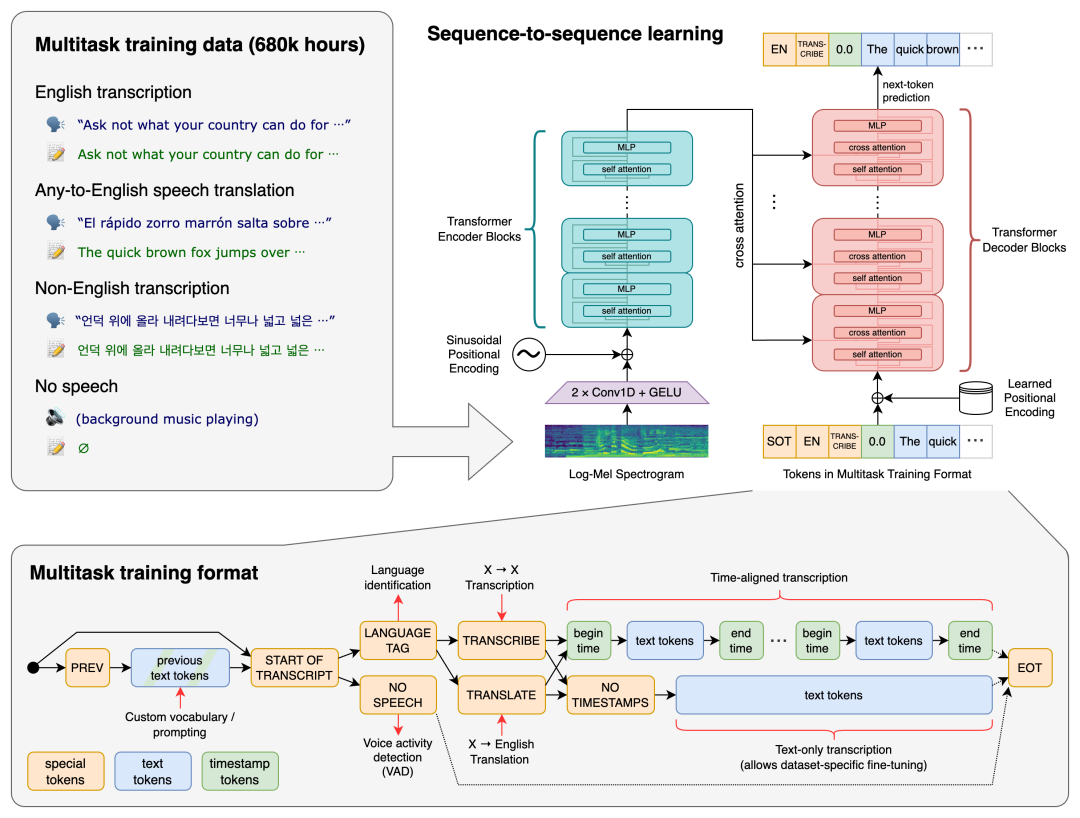
3.基于 AI 的语音输入工具 Whispo
https://github.com/egoist/whispo
深度学习驱动下的超智能语音处理神器,Whisper是 OpenAI 的一项语音处理项目,旨在实现语音的识别、翻译和生成任务。作为基于深度学习的语音识别模型,Whisper 具有高度的智能化和准确性,能够有效地转换语音输入为文本,并在多种语言之间进行翻译。按Ctrl键就可以开始录音,松开即可将语音转文字 转录内容可以自动插入到任何支持文本输入的应用中,数据存于本地
4.VAD (Voice Activity Detection) from ricky0123/vad-react
一个基于JavaScript的开源项目,旨在提供一个准确、用户友好的声音活动检测器(VAD),可在浏览器中运行。该项目通过使用VAD技术,能够实时检测音频流中的语音信号,从而进行后续的语音处理或资源释放。
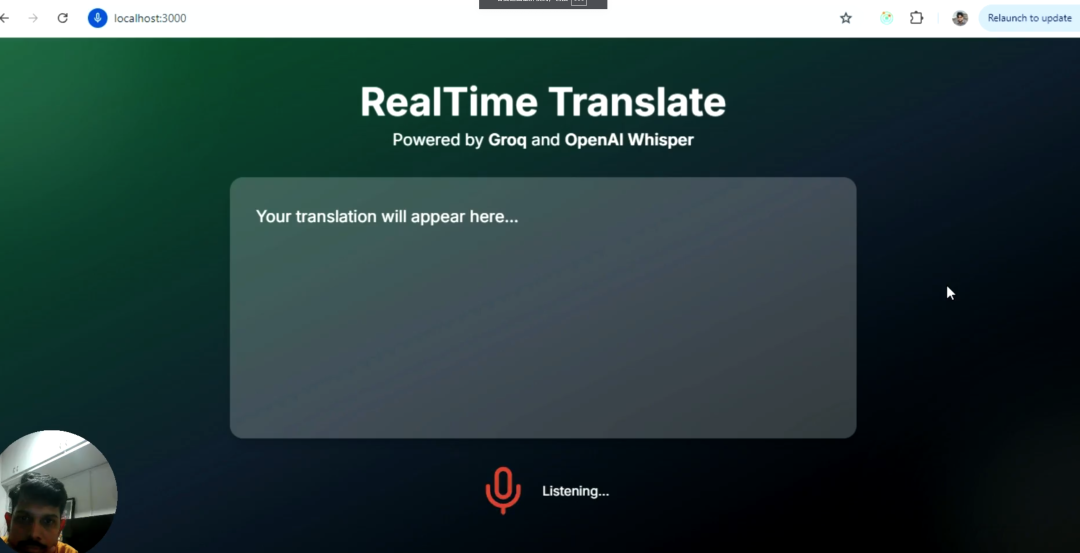
安装项目:通过npm安装vad-react包,具体命令如下:

运行示例:克隆项目并运行示例脚本,命令如下:

高赞科技基于AI语音识别技术的智能识音工牌产品,已为运营商,银行,车企,生活服务等行业提供:多形态识音硬件+行业垂类模型+营销数字化解决方案。如您想进一步了解,可以拨打咨询电话400-6138198,或者扫描/识别下方二维码添加业务专家微信,与我们联系。

添加业务专家了解更多
咨询电话|400-6138198