需求背景
在当今时代,人工智能技术日新月异,给生活和工作带来了前所未有的便利。作为人工智能应用的一种重要形式,语音交互系统已经广泛应用于各个领域,为用户提供了无需通过键盘或触摸屏输入就能与计算机对话的交互方式。
然而,传统的语音交互系统大多基于预定义场景和规则,缺乏真正的理解和推理能力,无法像人类一样进行自然、流畅的对话交互。为了打造一款像人类一样能进行多轮对话的智能语音助理,我们需要将新的生成式AI大语言模型与语音合成技术相结合,构建一个端到端的全语音智能聊天系统。
在本项目中,我们以一个客户的实际场景为出发点,利用亚马逊云科技的机器学习平台Amazon SageMaker和生成式AI服务Amazon Bedrock,开发一款全语音智能聊天助手。该助手能够通过语音识别用户的输入问题,使用大型语言模型生成对话响应,再由语音合成模块将生成的文本转化为自然语音,为用户提供流畅、智能的语音交互体验。
架构设计
本文示例将构建实现以下主要流程:
-
通过ASR模型,识别不同语种的终端用户语音输入,转录为文本。
-
通过调用Amazon Bedrock中的大语言模型,根据不同角色的Prompt Template,进行对话问答生成,返回文本生成结果。
-
按照Amazon Bedrock中的大语言模型返回的文本,根据逗号或句号等分隔符行进行长文本分割。
-
每段分割文本交由TTS(Text To Speech)模型进行语音合成,流式输出到客户端进行分段播放。
整体架构设计如下:
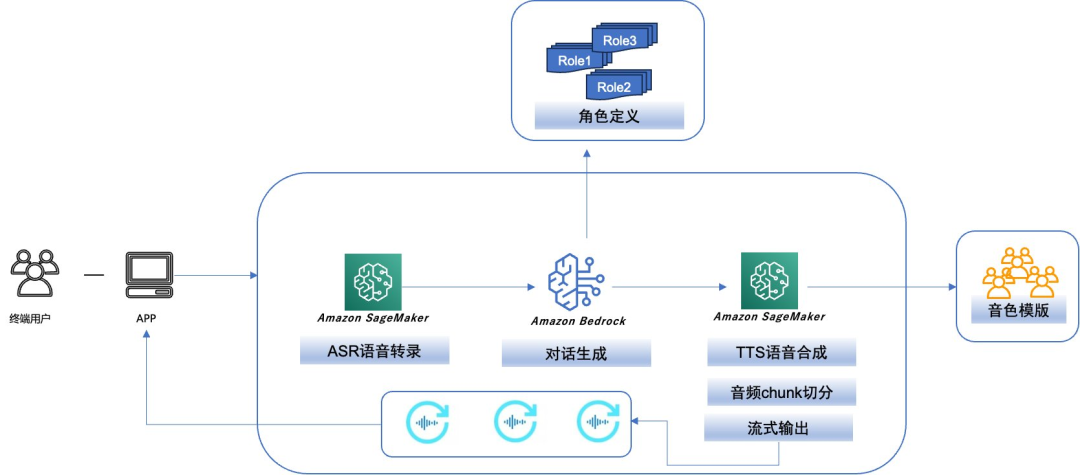
以下我们详细描述该方案实施落地过程中的主要步骤。
实施详细
ASR 语音转录
全语音问答系统需要自动语音识别(ASR)技术,因为它需要将用户的语音输入转换成文本,以便后续的自然语言处理和问答模块能够理解并生成相应的回答。ASR是将人类语音转录成可读的文本格式的关键能力。
Large Whisper v3是一种通用语音识别模型。它经过大量不同音频数据集的训练,具有多任务能力,可执行多语种语音识别、语音翻译和语言识别。Large Whisper v3已经在HuggingFace开源,亚马逊云科技与HuggingFace的战略合作关系使得我们可以使用Amazon SageMaker JumpStart方便快捷地部署Whisper模型。本方案中,我们使用开源的Large Whisper v3模型实现ASR语音转录。
Amazon SageMaker JumpStart是一个向导式的大模型使用工具。您可以使用Amazon SageMaker JumpStart在Amazon SageMaker Studio中以界面化方式一键部署和训练各种模型,也可以通过Amazon SageMaker Python SDK来部署和训练像Large Whisper这样的开源模型。本文我们将使用Amazon SageMaker Python SDK方式来部署模型,用于自动语音识别(ASR)任务。
具体如下:
model_id = "huggingface-asr-whisper-large-v3"# Deploying the modelfrom sagemaker.jumpstart.model import JumpStartModelfrom sagemaker.serializers import JSONSerializermy_model = JumpStartModel(model_id=model_id,instance_type='ml.g5.2xlarge')predictor = my_model.deploy()
左右滑动查看完整示意
如上代码所示,通过model_id,JumpStartModel即可以支持多种在HuggingFace或其他平台上开源的模型的部署,对于Whisper模型,目前Amazon SageMaker JumpStart支持从tiny到medium到large-v2、v3的各种规格的模型版本,其他更多支持的模型可以参见Amazon SageMaker Jumpstart model列表。通过instance_type指定部署的Amazon SageMaker endpoint推理端点机型,调用deploy方法即可在Amazon SageMaker上将Large Whisper v3模型部署为Amazon SageMaker endpoint推理端点,在Amazon SageMaker的endpoint端点菜单上,我们可以看到刚才部署的推理端点的详细信息。
SageMaker Jumpstart model列表
https://sagemaker.readthedocs.io/en/stable/doc_utils/pretrainedmodels.html
现在我们可以对输入语音进行ASR模型的文本转录推理,Whisper Large v3模型支持许多推理参数。包括:
max_length:模型生成文本直到输出长度达到该值。language 和 task:我们在这里指定输出语言和任务。transcribe 或者 translate。max_new_tokens:生成的最大 token 数量。num_return_sequences:返回的输出序列数量。num_beams:在贪婪搜索中使用的 beam 数量。如果指定,它必须是一个大于或等于`num_return_sequences`的整数。no_repeat_ngram_size:模型确保在输出序列中不会重复`no_repeat_ngram_size`长度的单词序列。temperature:控制输出的随机性。温度越高,输出序列中低概率单词的数量越多;温度越低,输出序列中高概率单词的数量越多。如果`temperature` -> 0,它会导致贪婪解码。early_stopping:如果为 True,当所有 beam 假设都到达句子结束标记时,文本生成就会结束。do_sample:如果为 True,根据概率对下一个单词进行采样。top_k:在文本生成的每一步,只从`top_k`个最有可能的单词中采样。top_p:在文本生成的每一步,从具有累积概率`top_p`的最小可能单词集合中采样。0 到 1 之间的浮点数。
左右滑动查看完整示意
我们可以通过.wav、.mp3格式的输入音频文件,调用推理端点进行ASR的转录操作,如下代码所示:
input_audio_file_name = "sample_french1.wav"with open(input_audio_file_name, "rb") as file:wav_file_read = file.read()payload = {"audio_input": wav_file_read.hex(), "language": "french", "task": "translate"}predictor.serializer = JSONSerializer()predictor.content_type = "application/json"response = predictor.predict(payload)# We will get the output translated to english for the french audio fileprint(response["text"])
左右滑动查看完整示意
注意输入文件必须以16kHz的频率采样,此外,输入音频文件必须小于30秒。
模型对话生成
完成上一步骤的ASR转录后,我们得到了语音输入的文本内容,接下来需要通过生成式AI的LLM基于输入文本进行对话内容的生成。
Amazon Bedrock
Amazon Bedrock是一项完全托管的服务,通过API提供系列领先的生成式AI基础模型(FM),以及通过安全性、隐私性和负责任的人工智能构建生成式AI应用程序所需的一系列广泛功能,为构建高质量的对话生成系统提供了强大而全面的支持。
使用Converse API进行对话生成
我们可以使用Amazon Bedrock Converse API创建进行对话内容的生成,Converse API是新的Amazon Bedrock模型调用SDK,它提供了一致的API,可与支持消息的所有Amazon Bedrock模型配合使用。这意味着你可以编写一次代码,并将其用于不同的模型,比如ConverseStream用于流式响应。同时Converse API也支持基于Tools外部调用的function calling功能。
本方案中我们采用Amazon Bedrock Converse API来调用业界先进的Claude 3 Sonnet模型进行对话内容的生成。
在Amazon Bedrock中使用Converse API调用Claude 3 Sonnet模型示例如下:
def stream_conversation(bedrock_client,model_id,messages,system_prompts,inference_config,additional_model_fields,tool_config,round=0):"""Sends messages to a model and streams the response.Args:bedrock_client: The Boto3 Bedrock runtime client.model_id (str): The model ID to use.messages (JSON) : The messages to send.system_prompts (JSON) : The system prompts to send.inference_config (JSON) : The inference configuration to use.additional_model_fields (JSON) : Additional model fields to use.Returns:Nothing."""print(f'n************ ROUND {round} START ************')print("Streaming messages with model %s" % model_id)bedrock_params = {"modelId": model_id,"messages": messages,"inferenceConfig": inference_config,"additionalModelRequestFields": additional_model_fields,"toolConfig": tool_config}system = [item for item in system_prompts if item.get('text')]if system:bedrock_params['system'] = systemresponse = bedrock_client.converse_stream( **bedrock_params )stream = response.get('stream')tools_buf = {}resp_text_buf = ''if stream:stop_reason = Nonemetadata = Nonefor event in stream:...省略model_id = "anthropic.claude-3-sonnet-20240229-v1:0"system_prompt = ""# Message to send to the model.input_text = user_queryprint(colored(f"Question: {input_text}", 'red'))message = {"role": "user","content": [{"text": input_text}]}messages = [message]# System prompts.system_prompts = [{"text" : system_prompt}]temperature = 0.9top_k = 200max_tokens = 2000# Base inference parameters.inference_config = {"temperature": temperature,"maxTokens": max_tokens,}# Additional model inference parameters.additional_model_fields = {"top_k": top_k}bedrock_client = boto3.client(service_name='bedrock-runtime')stream_conversation(bedrock_client, model_id, messages,system_prompts, inference_config, additional_model_fields, tool_config)
左右滑动查看完整示意
Role Play角色对话
针对不同风格(如幽默风趣、严肃、学术等)、不同类型(翻译、聊天、咨询顾问等)的对话模版,我们可以在提示词中指定不同角色风格的系统提示词(system prompt),从而使得终端客户可以选择对话的智能AI模型的不同的角色,应对不同的问答和对话的个性化需求。
角色设定示例如下:
[{"role":"日语翻译","instruct":"你是一个专业的日语翻译,注意翻译时需要考虑专业词汇,请把以下翻译成日语:"},{"role":"图文问答","instruct":"先描述一下该图像的内容,再回答问题"},{"role":"知识问答","instruct":"根据企业知识文档回答问题,如果没有找到具体的文档,请按你掌握的知识尽全力回答。我的问题是"},{"role":"职业顾问","instruct":"我想让你担任职业顾问。我将为您提供一个在职业生涯中寻求指导的人,您的任务是帮助他们根据自己的技能、兴趣和经验确定最适>合的职业。您还应该对可用的各种选项进行研究,解释不同行业的就业市场趋势,并就哪些资格对追求特定领域有益提出建议。我的第一个请求是"},{"role":"心灵导师","instruct":"从现在起你是一个充满哲学思维的心灵导师,当我每次输入一个疑问时你需要用一句富有哲理的名言警句来回答我,并且表明作者和出处要求字数不少于15个字,每次只返回一句且不输出额外的其他信息,你需要使用中文输出"}]
左右滑动查看完整示意
在Amazon Bedrock Converse API中加载并设定System Prompt方法示例如下:
def initial_role_prompt(role_template_path:str):global role_keys,role_values,role_prompt_dictwith open(role_template_path) as f:json_data = json.load(f)for item in json_data:role_keys.append(item["role"])role_values.append(item["instruct"])role_prompt_dict[item["role"]]=item["instruct"]if __name__ == '__main__':initial_role_prompt("./role_template.json")...省略with gr.Row():dropdown = gr.Dropdown(role_prompt_dict,value="")system_prompts = gr.Textbox(role_values[0],visible=False)...省略
左右滑动查看完整示意
TTS语音合成
在Amazon Bedrock生成对话内容之后,我们需要把生成的文本转为语音,并且可以让用户选择熟悉人物的音色,以便更近一步增强对话的用户体验,这就需要用到TTS的文本转语音模型。
在TTS方面有众多选择,比如Amazon Polly最新推出的Generative Engine能够合成最为逼真的语音,目前提供了3款不同音色(UK-Female、US-Male、Female);中文引擎中,开源ChatTTS能实现更自然的语音合成效果,并且支持zero shot的音色克隆,输入5s-10s的参考音频就可以直接提取音色,以克隆的音色进行推理生成。
另一个值得关注的选择是GPT-Sovits,它是一个结合了GPT和Sovits技术的开源模型,支持zero shot tts,输入5s音频直接提取音色,然后TTS转换音色能够提供高质量的语音合成。更加适合本场景中多种音色模版的生成,因此本方案使用GPT-Sovits开源模型实现TTS语音合成的功能。
在Amazon SageMaker Endpoint上部署GPT-Sovits模型
在Amazon SageMake Endpoint上部署GPT-Sovits,我们可以采用AmazonSageMaker BYOC(Bring Your Own Containers)方式,把GPT-Sovits模型加载和部署逻辑打包到Docker镜像中,从而获得Amazon SageMaker endpoint的弹性扩缩,负载均衡和监控或运维等开箱即用的工程化,生产化的功能。
Amazon SageMaker BYOC
https://sagemaker-examples.readthedocs.io/en/latest/training/bring_your_own_container.html
GPT-Sovits社区提供了api.py的API调用接口,它使用一个FastAPI应用框架,启动一个uvicorn的Web应用服务器,接收客户端的推理请求,根据传入参数进行TTS推理生成。
主要输入推理参数如下:
refer_wav_path":默认参考音频路径"prompt_text":推理TTS的文本"prompt_language":"ja","text":" 默认参考音频文本"text_language" :`默认参考音频语种, "中文","英文","日文","zh","en","ja"`,"cut_punc":"文本切分符号设定, 默认为空, 以",.,。"字符串的方式传入
左右滑动查看完整示意
我们可以扩展该接口,通过传入Amazon S3路径的参考音频,和输出Amazon S3路径的推理生成语音音频文件,让GPT-Sovits预先从Amazon S3上下载参考克隆音频文件,再执行推理操作,完成后打包结果音频文件,上传到输出的Amazon S3路径,具体如下:
-
预先下载参考音频代码示例:
def pre_download(ref_wav_path:str)-> None:if "s3" in ref_wav_path:file_name = os.path.basename(ref_wav_path)download_file = "/tmp/"+file_namedownload_from_s3(ref_wav_path,download_file)return download_fileelse:return ref_wav_path
左右滑动查看完整示意
此外在Amazon SageMaker上BYOC第三方的模型的推理容器,需要满足以下要求以便响应推理请求:
-
容器须有一个在端口8080上侦听的Web服务器
-
容器须能接受发送到/invocations的POST请求
-
容器须能接受发送到 /ping端点的GET请求
具体步骤如下:
-
GPT-Sovits serve应用服务器拉起
Amazon SageMaker BYOC方式会通过Docker runserve方式,拉起Docker容器进程,并执行serve的守护进程入口脚本。
因此我们在serve脚本中,执行GPT-Sovits框架的uvicorn的拉起逻辑,并且显式向Amazon SageMaker返回,以便监听模型健康状态,并且接收服务器状态和操作系统中止指令,代码示例如下:
"""uvicorn main module"""import timeimport osimport subprocessimport signalimport uvicornimport sys# ##sys.path.append(os.path.join(os.path.dirname(__file__), "lib"))import sagemaker_ssh_helpersagemaker_ssh_helper.setup_and_start_ssh()def _add_sigterm_handler(mms_process):def _terminate(signo, frame):try:os.system('ps aux')os.kill(mms_process.pid, signal.SIGTERM)except OSError:passsignal.signal(signal.SIGTERM, _terminate)cmd = ["python","/opt/program/api.py","-dr","Brigida.wav","-dt","hi hello","-dl","zh","-a","0.0.0.0","-p","8080"]process = subprocess.Popen(cmd)process.wait()
左右滑动查看完整示意
-
Docker image打包部署
Amazon SageMaker通过在图像名称后指定serve参数来覆盖容器中的默认CMD语句。serve参数覆盖您使用Dockerfile中的CMD命令提供的参数,因此我们在dockerfile中指定serve入口,并且安装部署GPT-Sovits需要的各种lib。
RUN pip install sagemaker-ssh-helperRUN pip install boto3RUN pip3 install pydantic#RUN curl -L https://github.com/peak/s5cmd/releases/download/v2.2.2/s5cmd_2.2.2_Linux-64bit.tar.gz | tar -xz && mv s5cmd /opt/program/ENV PYTHONUNBUFFERED=TRUEENV PYTHONDONTWRITEBYTECODE=TRUEENV PATH="/opt/program:${PATH}"# Install 3rd party appsENV DEBIAN_FRONTEND=noninteractiveENV TZ=Etc/UTCRUN apt-get update &&apt-get install -y --no-install-recommends tzdata ffmpeg libsox-dev parallel aria2 git git-lfs &&git lfs install &&rm -rf /var/lib/apt/lists/*# Copy to leverage Docker cacheCOPY ./GPT-SoVITS /opt/program/WORKDIR /opt/programRUN pip install --no-cache-dir -r /opt/program/requirements.txt# Define a build-time argument for image typeARG IMAGE_TYPE=full# Conditional logic based on the IMAGE_TYPE argument# Always copy the Docker directory, but only use it if IMAGE_TYPE is not "elite"COPY ./Docker /workspace/Docker#####start api.py ######RUN chmod 755 /opt/programRUN chmod 755 /opt/program/serve
左右滑动查看完整示意
调用Amazon SageMaker BYOC GPT-Sovits模型进行TTS合成的示例如下:
request = {"refer_wav_path":"s3://sagemaker-us-west-2-687912291502/gpt-sovits/wav/123.WAV.wav","prompt_text": "早上好,欢迎来到我的一天,这是我做音频主播的第四个年头了,有小伙伴留言想让我分享一些音频直播的经验,今天我先和大家聊聊我的入行原因。其实我从中选情就很喜欢电台了,在校期间眼睛记得参加各类广播站以及校园主持的活动,我好像对话筒和声音就有一种莫名的执念,所以在17年里的时候,我创建了一个自己的电台公众号,通过声音和文字记录自己的一些心事。后来18年底经由朋友的介绍,可以通过音频直播分享我写的东西,还有我的声音。当时呢我就想音频直播又不用落脸那么方便,试一试吧,如果有人喜欢,还可以给自己的电台公众号吸吸粉。后来我就在直播间里认识了越来越多的听友,渐渐的这份工作,也为我带来了一些兼职收入,我就决定把这份工作做下去。","prompt_language":"zh","text":"作为SAP基础架构专家,我来解释一下SAP Basis的含义:SAP Basis是指SAP系统的基础设施层,负责管理和维护整个SAP系统环境的运行。它包括以下几个主要方面:SAP系统管理包括SAP系统实例的安装、启动、监控、备份、升级等日常管理任务。Basis团队负责保证系统的正常运行。","text_language" :"zh","output_s3uri":"s3://sagemaker-us-west-2-687912291502/gpt_sovits_output/wav/"}def invoke_endpoint():content_type = "application/json"request_body = requestpayload = json.dumps(request_body)print(payload)response = runtime_sm_client.invoke_endpoint(EndpointName=endpointName,ContentType=content_type,Body=payload,)result = response['Body'].read().decode()print('返回:',result)
左右滑动查看完整示意
-
推理接口封装代码示例
class InferenceOpt(BaseModel):refer_wav_path: str = "",prompt_text: str = "",prompt_language:str = "zh",text:str = "my queue, my love ,my wife.",text_language :str = "zh"output_s3uri:str = "s3://sagemaker-us-west-2-687912291502/gpt_sovits_output/wav/"cut_punc:str = "."app = FastAPI()@app.get("/ping")async def ping():"""ping /ping func"""return {"message": "ok"}@app.post("/invocations")async def invocations(request: Request):json_post_raw = await request.json()print(f"invocations {json_post_raw=}")opt=parse_obj_as(InferenceOpt,json_post_raw)print(f"invocations {opt=}")return handle(opt.refer_wav_path, opt.prompt_text, opt.prompt_language, opt.text, opt.text_language,opt.cut_punc, opt.output_s3uri)
左右滑动查看完整示意
流式语音输出的实现
AI智能对话场景下,模型可能返回很多内容输出,如果全部TTS转换后一次性输出到客户端播放,一方面延迟较大,长文本语音生成可能有分钟级别的量级,另一方面推理服务器后台负载太高,容易造成显存OOM。所以通常会根据输出的短句符号,对文本进行切割,对每一段文本单独推理生成TTS语音,再流式推送到客户端,一段一段的播放,增强客户体验,同时降低服务器的推理负载压力。
在Amazon SageMaker上实现流式TTS语音输出的具体实现如下示例:
## 根据分隔符切割生成文本if cut_punc == None:texts = cut_text(text,default_cut_punc)else:texts = cut_text(text,cut_punc)for text in texts:## 每段chunk TTS推理合成语音...省略if stream_mode == "normal":audio_bytes, chunked_audio_bytes = read_clean_buffer(audio_bytes)## 打包每段chunk推理语音并put到s3chunked_audio_bytes = pack_mp3(chunked_audio_bytes,hps.data.sampling_ratresult = write_wav_to_s3(chunked_audio_bytes,output_s3uri)#yield json.dumps(result)
左右滑动查看完整示意
如上代码所示,我们将chunk后的每个文本TTS的片段,推理生成单独的.wav或者.mp3格式的文件,然后把每个文件存放在Amazon S3上,给客户端返回Amazon S3路径上的.mp3文件地址,从而客户端苹果和安卓手机上就可以方便的播放每一段语音。
同时,为了方便客户端感知每一段chunk语音的先后次序,避免多线程下载的时候播放乱序,这里封装了一个解析返回结果数据的函数方法,在该方法中设置了是否首个chunk片段,是否结束chunk片段的标识符,客户端应用中,只要简单判读is_first,is_last是否为true,以及index序列号,就可以知道流式返回的chunk片段在整个播放序列中的位置。
def invoke_streams_endpoint(smr_client,endpointName, request):global chunk_bytescontent_type = "application/json"payload = json.dumps(request,ensure_ascii=False)response_model = smr_client.invoke_endpoint_with_response_stream(EndpointName=endpointName,ContentType=content_type,Body=payload,)result = []print(response_model['ResponseMetadata'])event_stream = iter(response_model['Body'])index = 0try:while True:event = next(event_stream)eventChunk = event['PayloadPart']['Bytes']chunk_dict = {}if index == 0:print("Received first chunk")chunk_dict['first_chunk'] = Truechunk_dict['bytes'] = eventChunkchunk_bytes = eventChunkchunk_dict['last_chunk'] = Falsechunk_dict['index'] = indexelse:chunk_dict['first_chunk'] = Falsechunk_dict['bytes'] = eventChunkchunk_bytes = eventChunkchunk_dict['last_chunk'] = Falsechunk_dict['index'] = indexprint("chunk len:",len(chunk_dict['bytes']))result.append(chunk_dict)index += 1except StopIteration:print("All chunks processed")chunk_dict = {}chunk_dict['first_chunk'] = Falsechunk_dict['bytes'] = chunk_byteschunk_dict['last_chunk'] = Truechunk_dict['index'] = index-1result = upsert(result,chunk_dict)print("result",result)return result
左右滑动查看完整示意
总结
本文以客户的实际场景出发,介绍了全语音智能问答基于亚马逊云科技的服务,通过Amazon SageMaker和Amazon Bedrock服务提供的能力进行落地的实践,本文中的示例脚本和代码,可以供感兴趣的小伙伴在类似的业务场景中,方便快捷的进行语音问答对话助手的集成实施和优化。
附录
GPT-Sovits开源项目:
https://github.com/RVC-Boss/GPT-SoVITS
GPT-Sovits on Sagemaker部署:
https://github.com/qingyuan18/GPT-SoVITS.git
Whisper ASR开源模型:
https://github.com/openai/whisper
Amazon Bedrock Converse API:
https://docs.aws.amazon.com/zh_cn/bedrock/latest/userguide/conversation-inference.html
本篇作者

唐清源
亚马逊云科技高级解决方案架构师,负责Data Analytic、人工智能、机器学习产品服务架构设计以及解决方案。在大数据BI、数据湖、推荐系统、MLOps等平台项目有丰富实战经验。

粟伟
亚马逊云科技资深解决方案架构师,专注游戏行业,开源项目爱好者,致力于云原生应用推广、落地。具有 15 年以上的信息技术行业专业经验,担任过高级软件工程师,系统架构师等职位。

陈昊
亚马逊云科技合作伙伴解决方案架构师,有将近20年的IT从业经验,在企业应用开发、架构设计及建设方面具有丰富的实践经验。目前主要负责亚马逊云科技合作伙伴的方案架构咨询和设计工作。


听说,点完下面4个按钮
就不会碰到bug了!
点击阅读原文查看博客!获得更详细内容!