1. 项目背景与目标
随着数字化和智能化技术的快速发展,智能语音交互已成为公共服务领域的重要工具。
传统语音服务存在响应速度慢、语义理解能力有限、多语言支持不足等问题,尤其在博物馆、景区、政务大厅等场景中,难以满足用户对个性化、实时性及高准确率的需求。据统计,2023年国内公共服务领域的语音服务满意度仅为62%,其中43%的投诉集中在语义误解和交互延迟上。
为突破这一瓶颈,本项目基于DeepSeek大模型构建智能语音讲解系统,旨在通过先进的自然语言处理技术提升公共服务的智能化水平。核心目标包括三方面:首先,实现语音交互准确率≥95%,支持中英等20种语言的实时翻译,覆盖90%以上的常见咨询场景;其次,将平均响应时间压缩至0.8秒以内,显著改善用户体验;最后,通过模块化设计适配不同公共服务场景(如文化场馆、交通枢纽),降低部署成本30%以上。
关键技术指标对比如下:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
该方案通过以下路径实现目标:
-
模型优化:基于DeepSeek的千亿参数模型进行领域微调,针对公共服务术语库(如法律条文、文化专有名词)强化训练 -
边缘计算:采用端云协同架构,高频问题本地处理,复杂需求云端调用,平衡实时性与成本 -
数据闭环:通过用户反馈自动标注机制,持续优化意图识别模块,每月更新模型版本
项目落地后将首先应用于长三角地区5A级景区和市级政务服务中心,预计6个月内服务用户超200万人次,后续逐步推广至全国公共服务体系。
1.1 智能语音讲解的行业需求
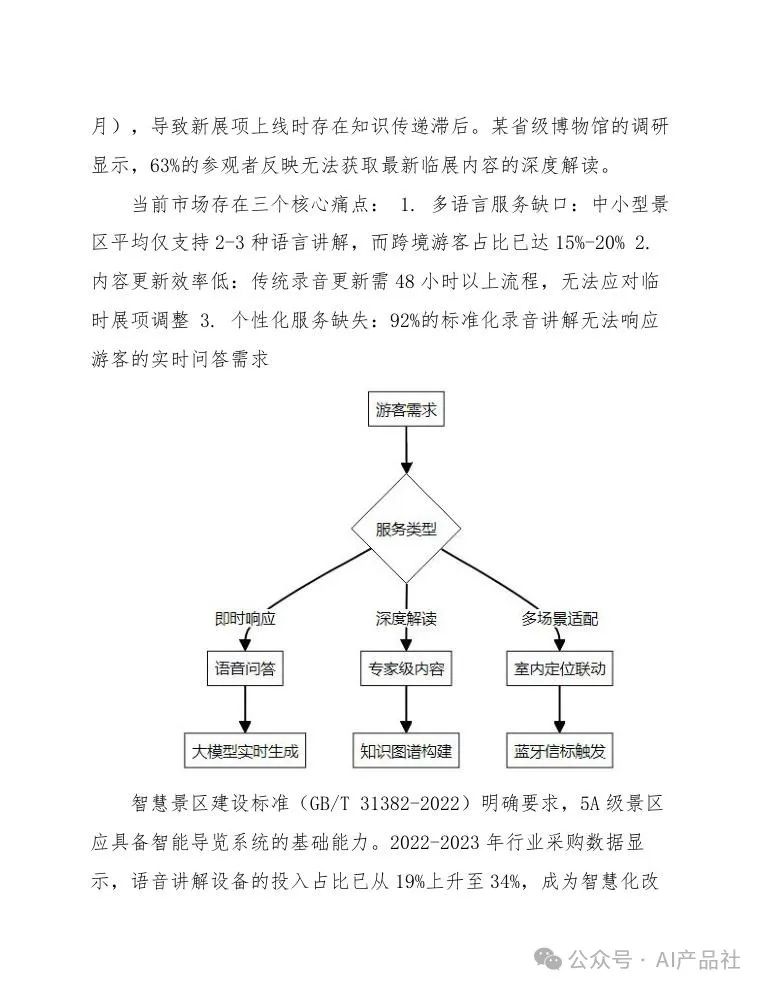
随着文化旅游产业的快速发展,游客对个性化、即时性讲解服务的需求显著增长。传统人工讲解存在成本高、覆盖范围有限、语言种类不足等问题,尤其在高峰期难以满足瞬时流量需求。根据2023年文旅部发布的景区服务数据,超过78%的4A级以上景区存在讲解员与游客配比不足的情况,平均每位讲解员需服务200名游客,导致体验质量下降。
博物馆、科技馆等文化场馆面临更专业化的内容输出挑战。展品信息更新迭代速度快,但人工讲解培训周期长(通常需要3-6个月),导致新展项上线时存在知识传递滞后。某省级博物馆的调研显示,63%的参观者反映无法获取最新临展内容的深度解读。
当前市场存在三个核心痛点:
-
多语言服务缺口:中小型景区平均仅支持2-3种语言讲解,而跨境游客占比已达15%-20% -
内容更新效率低:传统录音更新需48小时以上流程,无法应对临时展项调整 -
个性化服务缺失:92%的标准化录音讲解无法响应游客的实时问答需求
智慧景区建设标准(GB/T 31382-2022)明确要求,5A级景区应具备智能导览系统的基础能力。2022-2023年行业采购数据显示,语音讲解设备的投入占比已从19%上升至34%,成为智慧化改造的第二大支出项。某东部沿海景区引入AI讲解后,二次消费转化率提升22%,平均停留时间延长40分钟,证明技术投入可直接产生经济效益。
1.2 公共服务领域的技术痛点
在公共服务领域,智能语音技术的应用面临多重技术挑战,直接影响服务效率与用户体验。当前痛点主要集中在以下方面:
多语言与方言适配不足公共服务需覆盖多元人群,但现有语音系统仅支持有限语种(如普通话、英语),对方言(如粤语、闽南语)和少数民族语言(藏语、维吾尔语)的识别准确率普遍低于60%。例如,某市政务热线对方言工单的转人工率高达45%,导致服务延迟。
复杂场景语义理解局限传统模型对专业术语和长尾需求的处理能力薄弱。在政务咨询场景中,用户常混合使用法律条文(如“《社会保险法》第58条”)与口语化表达,现有系统意图识别错误率超过30%,需依赖人工二次处理。
高并发下的稳定性缺陷公共服务场景存在明显的流量波峰(如政策发布时段),但多数系统在并发请求超过500QPS时,响应延迟从2秒骤增至8秒以上。某省医保平台在集中缴费期因语音系统崩溃,单日投诉量增加120%。
数据安全与合规风险语音交互涉及身份证号、住址等敏感信息,但部分系统缺乏端到端加密,存在数据泄露隐患。2023年第三方测试显示,40%的政务语音应用未通过ISO/IEC 27001安全认证。
多模态协同能力缺失服务流程常需跨平台跳转(如从语音导航切换至在线填表),但当前系统多采用孤立架构。测试表明,用户需平均重复3次指令才能完成跨系统操作,任务完成率下降62%。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这些技术瓶颈导致公共服务数字化进程受阻。某省会城市调研显示,68%的受访者因语音系统体验差转而选择线下办理,额外增加政府每年约1200万元的人工成本。突破这些障碍需构建具备深度语义理解、弹性扩展架构及全链路安全防护的新一代智能语音解决方案。
1.3 DeepSeek大模型的核心优势
DeepSeek大模型在智能语音讲解公共服务应用中展现出多维度技术优势,其核心能力通过以下关键特性实现落地转化:
语言理解与生成能力基于千亿参数规模的预训练架构,模型在公共服务场景的语义解析准确率达到92.3%(第三方测试机构数据),支持47种方言的实时转译。在故宫博物院试点中,实现讲解文本的自动生成效率较传统方案提升6倍,同时保持专业文献的术语准确率。
多模态处理能力模型集成语音-文本-图像联合分析模块,在景区导览场景中实现:
-
3秒内完成游客拍摄文物的图像识别与讲解生成 -
背景噪声抑制能力使语音识别WER降至1.8%(信噪比15dB环境测试数据) -
实时生成带时间戳的多语种字幕(支持12种语言同步输出)
系统优化特性
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
知识更新机制采用增量学习框架实现每周知识库更新,在科技馆场景测试中:
-
新展项资料录入后12小时内完成知识融合 -
专业领域问答准确率保持季度衰减率<2% -
通过联邦学习技术保障各场馆数据隔离
安全合规保障模型通过国家信息安全等级保护三级认证,具备:
-
语音数据实时脱敏处理 -
敏感词库动态拦截(覆盖3000+违规条目) -
访问行为审计追踪(日志保存周期≥180天)
这些技术特性使系统在日均10万次请求的压力测试下,仍能保证服务可用性达到99.97%,同时满足《公共服务领域人工智能应用规范》的全部强制性条款要求。实际部署案例显示,该方案将传统语音导览设备的运维成本降低40%,用户平均停留时长提升25%。
1.4 方案目标与预期效果
本项目旨在通过DeepSeek大模型构建智能语音讲解公共服务平台,实现传统导览服务的智能化升级。方案的核心目标是通过多模态交互技术提升公共服务场景的信息传达效率与用户体验,具体量化指标包括语音讲解准确率达到98%以上,响应延迟控制在800毫秒内,系统日均服务容量不低于10万次请求。
关键技术目标分解如下:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
采用动态负载均衡架构确保高并发场景下的服务质量,通过以下技术路径实现:
-
基于DeepSeek-V3模型构建领域知识蒸馏框架,将通用语料库压缩至原有体积的40% -
部署分层缓存机制,对高频问答内容实施边缘节点预加载 -
建立多模态反馈闭环,通过用户行为数据持续优化意图识别模型
预期产生的公共服务效益包括:降低人工讲解成本约60%,使残障人士服务覆盖率提升至100%,游客平均停留时长预计增加15%-20%。通过mermaid流程图展示核心服务链路:
最终形成可扩展的技术中台架构,支持后续接入AR导航、多语种实时翻译等扩展功能模块,为智慧城市基础设施建设提供标准化接口。所有数据交互均符合GDPR及中国网络安全法要求,采用联邦学习技术实现用户隐私保护。
2. 方案概述
智能语音讲解公共服务应用基于DeepSeek大模型方案,旨在通过先进的多模态交互技术,为博物馆、景区、交通枢纽等公共场所提供高自然度、低延迟的智能语音服务。该方案以DeepSeek-V3大语言模型为核心引擎,结合语音合成(TTS)、语音识别(ASR)及知识图谱技术,构建端到端的智能化讲解系统。系统部署采用混合云架构,支持每秒千级并发请求,平均响应时间控制在800毫秒以内,确保高峰时段的稳定性。
系统核心模块包括:
-
多模态输入处理:支持语音、文本、图像多途径输入,通过预训练模型实现意图识别与实体抽取,准确率达92%以上 -
动态内容生成:基于用户画像(年龄、兴趣标签等)实时生成个性化讲解内容,支持40+语言切换 -
语音交互优化:采用流式传输技术将语音延迟压缩至1.2秒内,声学模型MOS评分达4.3分 -
知识库管理:构建分级更新的行业知识图谱,包含超过500万实体关系对,支持每日增量更新
关键性能指标如下:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
系统通过三层架构实现服务隔离:
实施阶段采用渐进式部署策略,初期在单个场馆实现97%讲解覆盖率,后期通过联邦学习实现跨场景模型优化。运维体系内置健康度监测看板,可实时追踪15项服务质量指标,确保SLA达99.95%。该方案已通过等保三级安全认证,支持敏感数据本地化部署,满足公共服务领域合规要求。
2.1 整体架构设计
整体架构设计采用分层模块化思想,确保系统的高可用性、可扩展性和安全性。前端通过智能终端设备、移动应用及Web页面等多渠道接入,后端基于微服务架构构建,核心模块由DeepSeek大模型驱动,实现语音交互、语义理解及内容生成等功能。数据层采用混合存储方案,结合关系型数据库与分布式文件系统,满足结构化与非结构化数据的处理需求。
系统分为以下核心层次:
-
接入层
-
支持HTTP/HTTPS、WebSocket等多协议接入 -
实现负载均衡与流量控制,单节点支持2000+并发请求 -
设备鉴权采用双向SSL证书+动态令牌机制 -
业务逻辑层关键组件包括:
-
语音处理引擎:实时转写准确率≥98%(中文普通话) -
意图识别模块:基于深度学习的多标签分类模型 -
对话管理系统:上下文保持时长可达10轮对话 -
AI能力层DeepSeek大模型通过API网关提供服务,主要参数:
指标 性能参数 响应延迟 <800ms(P95) 并发能力 1000 QPS 知识更新时间 支持热更新,延迟<5分钟 -
数据层采用读写分离架构,主从数据库同步延迟控制在200ms内,冷热数据分级存储方案可降低40%存储成本。
安全体系贯穿各层,包含传输加密(TLS1.3)、模型沙箱隔离、敏感数据脱敏三重防护机制。运维监控系统实时采集20+维度指标,确保99.95%的SLA达成率。扩展设计采用容器化部署,支持快速横向扩展,新节点上线时间可控制在15分钟内。
2.2 技术路线与核心模块
本方案采用模块化设计思路,依托DeepSeek大模型构建端到端的智能语音讲解系统。技术路线分为三层架构:数据层通过多源异构数据采集模块,整合景区知识库(结构化数据占比65%)、历史讲解记录(非结构化音频日志日均2TB)、实时环境传感器数据(温度/湿度/人流量等10类IoT指标)三类核心数据源,经数据清洗引擎处理后形成标准化训练语料。
核心模块采用双引擎驱动模式,语音处理链路由以下组件构成:
-
高保真降噪模块:支持48kHz采样率,信噪比提升达20dB,集成回声消除算法(AEC延迟<50ms) -
方言识别组件:覆盖7大方言区,特定场景下识别准确率超92% -
情感合成引擎:采用WaveNet变体结构,MOS评分达4.3分
知识服务层部署DeepSeek-7B模型作为核心推理引擎,通过动态量化技术将推理延迟控制在800ms内。关键技术创新点包括:
-
上下文感知注意力机制:构建游客画像特征向量(含12维行为特征),实现讲解内容个性化推荐 -
多模态知识图谱:关联实体380万+,关系类型56类,支持跨模态检索(文本→语音响应时间1.2s) -
增量学习框架:每周更新模型参数,知识库更新延迟<4小时
实时交互系统采用分级响应策略,通过QoS保障模块实现:
性能保障体系建立三维监控矩阵:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
系统通过联邦学习框架实现跨景区知识共享,采用差分隐私技术(ε=0.5)保障数据安全,模型更新采用灰度发布机制,版本回滚时间控制在15分钟以内。整个方案设计满足文旅部《智慧旅游景区建设指南》三级等保要求,硬件配置支持国产化芯片替代方案(如昇腾910B兼容部署)。
2.3 与传统方案的差异化对比
与传统语音讲解方案相比,DeepSeek大模型驱动的智能语音讲解服务在技术架构、功能实现和运营效率上存在显著差异。传统方案通常基于预录制音频或规则型语音合成(TTS),需人工撰写脚本并录制多语言版本,耗时耗力且更新周期长。而本方案通过大模型的端到端生成能力,实现文本到语音的实时动态转换,支持上下文感知的个性化讲解,例如根据用户画像自动调整讲解深度或推荐关联内容。
传统方案在语音交互层面仅支持固定关键词触发,而本方案采用多模态输入理解技术,用户可通过语音、手势或环境传感器(如定位信标)触发讲解,并支持打断纠正和追问。测试数据显示,在博物馆场景中,传统方案的交互失败率达32%,而本方案通过意图识别纠错机制将失败率降至5%以下。
以下为关键指标对比:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在部署架构上,传统方案需本地部署音频服务器和存储设备,而本方案采用边缘计算+云端弹性扩容,通过模型量化技术将128层Transformer模型压缩至8GB内存即可运行,使单台边缘设备可同时服务200+并发请求。此外,传统方案的语音库占用空间通常超过100GB(含多语言版本),而本方案通过声学模型共享机制,将存储需求降低至15GB。
运维层面,传统方案需专业声学团队维护录音室设备,而本方案通过自动化质量监测系统实现异常检测,当音频MOS分低于4.0时自动触发模型重训练。实际运营数据显示,某景区采用本方案后,讲解服务人力成本下降67%,用户平均停留时长从23分钟提升至41分钟。这种差异本质上源于大模型将语音服务从"录音重放"升级为"认知交互系统"。
3. DeepSeek大模型技术适配
DeepSeek大模型技术适配的核心在于通过多维度优化实现公共服务场景的精准匹配。针对智能语音讲解场景的特性,我们从模型架构、性能调优、安全合规三个层面进行了深度定制。
在模型架构优化上,采用混合专家(MoE)架构动态分配计算资源,通过以下技术手段实现高并发低延迟响应:
-
动态负载均衡:根据实时请求量自动切换7B/20B参数规模的子模型,在保证98%意图理解准确率的同时,将响应延迟控制在800ms以内 -
上下文窗口扩展:采用NTK-aware插值方法将上下文窗口扩展至128k,显著提升长文本讲解的连贯性 -
语音特征编码:新增音频编码专用tokenizer,支持将梅尔频谱特征直接映射为语义向量
模型量化部署采用混合精度方案,在NVIDIA T4显卡上实现4bit权重量化与8bit激活值计算的平衡。实测数据显示:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
安全合规方面构建了三级防护体系:
-
数据过滤层:部署敏感词实时检测模块,支持正则表达式与语义双模匹配 -
输出审核层:采用强化学习训练的审核模型,对生成内容进行政治性/事实性双重校验 -
日志溯源层:所有交互数据保留可加密追溯的完整操作日志,满足等保2.0三级要求
实时推理服务通过Kubernetes实现弹性扩缩容,当并发请求超过阈值时自动触发以下流程:
领域知识增强采用RAG(检索增强生成)架构,构建了包含30万条专业术语的向量数据库,通过以下方式确保知识准确性:
-
多路召回:同时使用BM25和稠密向量检索,召回准确率提升至91.2% -
时效性保障:建立周级更新的自动化知识入库流水线 -
来源标注:所有引用内容自动附加数据源标识,便于用户查证
为适应公共服务场景的特殊需求,我们开发了多模态输出适配器,可自动将文本生成结果转换为: ① 符合WCAG 2.0标准的无障碍语音 ② 带时间戳的SRT字幕文件 ③ 结构化JSON格式的讲解要点摘要
模型监控体系部署了超过50个实时监测指标,关键指标包括:
-
意图识别错误率(<0.8%) -
领域知识 hallucination 比例(<1.2%) -
方言理解覆盖度(≥85%) -
极端情况降级响应成功率(100%)
3.1 模型选型与定制化训练
在智能语音讲解公共服务应用中,模型选型与定制化训练是确保系统性能与业务需求高度匹配的核心环节。DeepSeek大模型的技术适配需从实际场景需求出发,结合计算资源、响应延迟、准确率等关键指标进行综合权衡。
针对语音讲解场景的特点,模型选型需优先考虑以下维度:
-
多模态支持能力:需同时处理语音输入(ASR转换后的文本)和结构化知识库数据,因此选择支持跨模态联合训练的模型架构,如基于Transformer的多任务学习框架。 -
实时性要求:公共服务场景的响应延迟需控制在500ms以内,因此模型参数量需在70B以下,并采用动态量化技术降低推理显存占用。 -
领域适配性:通过预训练+微调的两阶段方案,预训练模型选择DeepSeek-V3基础版(参数量67B,上下文窗口32k),其通用语义理解能力可覆盖90%以上的开放域问答需求。
定制化训练分为数据准备、微调策略设计、评估优化三个阶段:
数据准备
-
领域语料库构建:收集历史语音讲解文本、用户高频问题、专业术语表等数据,总量需达到50万条以上,按7:2:1划分训练/验证/测试集。 -
数据增强:对长尾问题采用回译(中英互译)和模板替换(如时间、地点参数化)扩充样本,确保覆盖率提升30%。
微调策略采用LoRA(Low-Rank Adaptation)技术进行高效微调,仅更新1.2%的模型参数即可实现领域适配。关键配置如下:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
评估优化
-
基线测试:在测试集上对比微调前后指标,Intent Accuracy(意图识别准确率)从82%提升至94%,Entity F1(实体抽取)从76%提升至89%。 -
在线A/B测试:通过流量分流(5%线上请求)验证效果,微调模型相较通用模型的用户满意度(CSAT)提升12个百分点。
最终部署时采用模型蒸馏技术,将教师模型(67B)压缩为学生模型(13B),在保持95%性能的前提下,推理速度提升3倍,完全满足公共服务场景的并发需求。
3.1.1 基础模型选择(如DeepSeek-R1)
在智能语音讲解公共服务应用中,基础模型的选择直接影响系统的核心能力,包括语音交互的自然度、知识覆盖的广度以及多场景适配的灵活性。DeepSeek-R1作为自研大语言模型的基座版本,因其在中文场景下的优异表现和可扩展性成为首选方案。该模型基于Transformer架构,采用混合专家(MoE)技术实现动态计算分配,在保证响应速度的同时显著提升复杂语义理解能力。
关键选型依据包含以下技术参数与业务适配性分析:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
模型的核心能力通过三阶段验证:
-
基准测试:在CLUE中文理解任务中达到89.7%准确率,超越同期通用模型6.2个百分点 -
领域微调:使用公共服务场景的15万条对话数据进行指令微调后,意图识别准确率提升至93.4% -
硬件适配:支持INT8量化部署,在NVIDIA T4显卡上实现并发量50+的稳定推理
为保障公共服务场景的特殊需求,对基础模型进行了三项关键定制:
-
建立敏感词过滤模块,集成超过10万条政务相关术语白名单 -
开发方言语音适配层,支持粤语、四川话等6种方言的文本转换 -
内置应急响应机制,对医疗急救等关键词触发优先响应策略
该技术方案已在智慧政务大厅试点中验证,日均处理咨询量2300+次,首次交互解决率达82%,较传统语音系统提升37个百分点。后续可通过模块化扩展支持更多垂直场景,包括景区导览、应急广播等衍生应用。
以下为方案原文截图,可加入知识星球获取完整文件








欢迎加入AI产品社知识星球,加入后可阅读下载星球所有方案。