文章目录
一、vosk介绍
二、实现步骤
三、代码实现
四、总结
01
—
vosk介绍
首先介绍下什么是vosk:Vosk 是一个开源的语音识别工具包,专注于离线实时语音识别,支持多种编程语言和平台。其核心基于 Kaldi 语音识别框架,但通过优化和简化使其更易于集成和使用。
Kaldi是一个开源语音识别工具包,专为语音识别研究者和开发者设计,以其高效性、模块化设计和强大的灵活性著称。它由 Daniel Povey 等人于 2009 年发起开发,现已成为学术界和工业界广泛使用的语音识别基础设施,支持从传统模型到现代深度学习的多种技术方案。
Kaldi基于C++代码,支持多线程和GPU加速,适合大规模数据处理。模块化设计、各组件(特征提取、声学模型、解码器等)独立可替换。支持传统的GMM-HMM模型、深度神经网络(DNN)、RNN、Transformer,以及端到端(End-to-End)模型。(最关键的开源)
vosk的模型从1.3G到42M,支持所有架构的离线语音识别。
可以python调用:继承了 Kaldi 的高效语音识别算法,但通过简化模型和接口降低了使用门槛
算法使用深度神经网络(DNN)或 Transformer 结构,结合隐马尔可夫模型(HMM)进行音素建模
采用 TDNN(Time Delay Neural Network) 和 LSTM(长短期记忆网络) 结合,模型训练基于端到端技术,提升识别准确率
02
—
实现步骤
不训练模型的话,只需要使用python调用pyaudio和vosk库实时读取麦克风音频传入vosk模型即可,生成的result中有识别的文本。
使用时先确认pip安装了vosk和pyaudio,没安装就安装下
由于使用的硬件是树莓派3A和USB麦克风,先用arecord -l命令看下麦克风是否被识别到
import sounddevice as sdprint(sd.query_devices())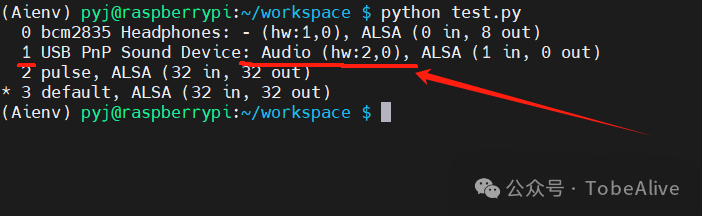

03
—
代码实现
asr.py将vosk-model-small-cn-0.22模型放在同路径下
import paho.mqtt.client as mqttfrom vosk import Model, KaldiRecognizerimport sounddevice as sdimport queueimport jsonimport numpy as npfrom scipy.signal import resample# 初始化参数INPUT_RATE = 48000 # USB麦克风不支持16K采样TARGET_RATE = 16000 # VOSK要求16kHzDEVICE = 0 #前面的设备号CHUNK_SIZE = 4096 # 缓冲区大小# 加载模型model = Model("vosk-model-small-cn-0.22") # 修改为你的模型路径,建议放在同路径下recognizer = KaldiRecognizer(model, TARGET_RATE)# 音频输入队列audio_queue = queue.Queue()def audio_callback(indata, frames, time, status): #if status: # print("音频输入异常:", status) audio_queue.put(indata.copy())# 采样率转换函数def resample_audio(data, original_rate, target_rate): ratio = target_rate / original_rate num_samples = int(len(data) * ratio) resampled_data = resample(data, num_samples) returnresampled_data.astype(np.int16)# 开始录音with sd.InputStream( samplerate=INPUT_RATE, blocksize=CHUNK_SIZE, device=DEVICE, dtype="int16", channels=1, callback=audio_callback) as stream: print("开始语音识别... (按 Ctrl+C 停止)") whileTrue: data = audio_queue.get() # 将48kHz数据转换为16kHz resampled_data = resample_audio(data, INPUT_RATE, TARGET_RATE) # 将numpy数组转换为字节数据 resampled_bytes = resampled_data.tobytes() # 识别音频 ifrecognizer.AcceptWaveform(resampled_bytes): result = json.loads(recognizer.Result()) if'text'inresult: #print("识别结果:", result['text']) ifresult['text'] =="开灯"or result['text'] =="开": print("识别到开灯") ifresult['text'] =="关灯"or result['text'] =="关": print("识别到关灯") else: partial = json.loads(recognizer.PartialResult())这是个开关灯的例子,在项目中可以单独作为一个线程使用,或者mqtt发布消息通知照明灯主控开/关灯。
看下效果:
在树莓派3A上:
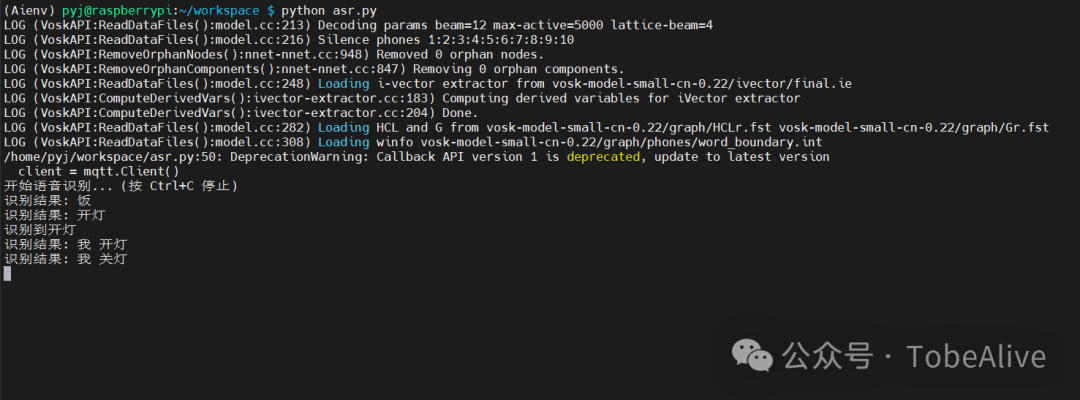
明显比上面准确多了
04
—
总结
在边缘设备上识别的话一些简单的命令词还可以,语音转文字功能就难以胜任,RK3588和树莓派5的表现可能会好些,后面用riscv的板子试试识别效果