点击蓝字 关注我们

重庆大学穆小静和李东晓教授等人,在《Nature Communications》上发布了一篇题为“Machine learning-assisted wearable sensing systems for speech recognition and interaction”的论文。论文内容如下:
一、摘要
二、背景介绍
人体会产生大量的生物信号,这些信号可被检测、数字化、分析,并能与外部设备进行交互。 在这些信号中,人类的声音尤为显著,它在时间、频率和幅度域都具备丰富的信息传输能力。这种强大的信息承载能力使声音成为生物通信、人机交互(HMI)和物联网(IoT)应用中的关键要素,这些应用涵盖智能家居、远程控制、身份识别以及基于语音的系统等。然而,基于空气振动的语音通信容易受到背景噪声(如路边、商场、车站等嘈杂环境)和声学介质(如火灾现场、医院、水下等特殊场景)的干扰和阻碍。此外,发声过程依赖于一个协调的器官系统,任何因肌萎缩侧索硬化症(ALS)、中风、帕金森病或喉癌等病症导致的损伤,都可能严重影响语音清晰度和识别效率。为应对这些挑战,研究人员开发了先进的降噪算法和多麦克风系统来提升语音处理能力。然而,这些解决方案的有效性受到声音信号质量和多特征参数复杂性的限制。例如,单麦克风系统无法捕捉空间特征,并且难以提供高信噪比的音频信号。虽然多麦克风系统及相关算法能改善语音信号处理,但它们需要复杂的工程设计,且占用更多空间。
近年来,基于面部和唇部运动的视觉语音识别作为一种增强嘈杂环境中语音感知的方法逐渐受到关注。虽然这种方法在挑战性的声学条件下提高了语音感知质量,但它需要额外的摄像头,从而增加了系统的复杂性并降低了实用性。近年来,直接监测面部运动状态的可附加传感器作为无声语音识别的解决方案引起了关注。尽管面部特征在一定程度上可以补充音频信号,但在捕捉音高、音色和声音强度等声学参数方面存在显著局限性。相反,将传感器直接放置在发声器官区域提供了一种有效的方式来实现全面的声音信息收集。传统的监测声音信号的可穿戴设备通常通过带子或粘贴补丁附着在身体上。然而,它们的刚性和扁平形状限制了实际应用。柔性材料和传感技术的发展为不可感知的皮肤可穿戴设备铺平了道路。目前,安装在发声器官中的柔性传感技术主要包括石墨烯、柔性表面肌电图电极、压阻和摩擦电效应。与传统的刚性麦克风相比,这些技术佩戴更为舒适,并能无缝融入日常活动中。尽管具有这些优势,这些传感器通常依赖于有线硬件,限制了其日常使用的适应性。
为克服这些挑战,集成的柔性可穿戴设备与信号处理和传输单元的结合至关重要,以充分利用各种机电特性的潜力。微电机械系统(MEMS)制造技术的进步为提高可穿戴设备的集成度带来了希望。一项显著的创新是将商业MEMS加速度计芯片纳入可穿戴设备,使得对机械声信号(如语音、吞咽、呼吸和心脏运动)的持续监测成为可能。然而,当前的传感器未能满足宽频带范围和平坦度的要求,限制了信号频谱的能量分布。此外,检测皮肤加速度仅提供肌肉运动模式数据,忽视了声带器官的关键振动信息。这一生物特征信息的缺失导致在监测小幅度肌肉运动时机械声信号相对较弱。这一局限性对于皮肤组织较厚的用户(如甲状腺肿大者)或喉部受伤者尤其不利。因此,有必要开发一种新的便携式语音交互系统,以解决这些问题并提升用户体验和人机交互。
在本研究中,作者展示了一种可穿戴的皮肤附着式声学传感器(SAAS),该传感器旨在在嘈杂环境中进行语音识别和人机交互。压电微机械超声换能器(PMUT)是该系统的核心传感元件,具有体积小、高灵敏度、宽带宽和优良的平坦性等特点。为了增强传感系统的集成度和佩戴舒适性,作者采用了软电子技术和弹性体封装技术。在设备封装中,作者使用了空间隔离和蛇形导电线,以机械方式将传感元件与支持电子设备分离,从而最小化电路噪声的干扰并提高测量灵敏度。所开发的SAAS对声带肌肉运动和声带振动表现出高度敏感性,使其能够在10 Hz至20 kHz的宽频率范围内捕捉高质量信号,同时有效减少环境噪声干扰。 在将SAAS与商业麦克风进行比较的演示中,系统在恶劣声学环境和口罩下基本不受影响。此外,通过在增加头部运动和变化颈部位置的条件下进行测试,验证了SAAS的稳健性和灵活性。这些特性使得SAAS无需精确放置,并显著减少了声学信号捕捉中的运动伪影干扰。基于SAAS获取的丰富生物特征信息,并结合人工智能,作者在音素、声调和相似发音词汇分类等任务中分别达到了99.5%、100%和96.9%的准确率。这一卓越表现突显了其在基于可穿戴声学设备的身份识别和安全系统中的潜力。此外,作者还展示了可穿戴声学设备在人机交互和物联网控制中的优势。最后,作者收集了参与者日常生活中的十个句子,并使用深度学习进行了分类,准确率达到了99.8%。这些结果表明,高度集成的可穿戴声学传感器不仅能够在恶劣声学环境中有效执行语音识别,而且在涉及言语障碍患者的语音交互应用中展现出巨大的潜力。
三、内容详解
3.1 SAAS的感知机制
SAAS的传感机制和关键功能如图1所示。如图1a所示,SAAS在HMI中的信息流得以展示。例如,当参与者希望控制一只机器人狗从四足站立姿势过渡到直立姿势时,他们会利用发声器官发出相应的语音指令。然而,在嘈杂环境中,这些语音指令无法通过空气直接传输到机器人狗,因为受到干扰。为了解决这一限制,作者开发了一种可以直接贴附于喉部的传感器。该传感器能够捕捉发声器官产生的声学信号,即使在嘈杂环境中也能有效工作。随后,传感器通过集成信号处理电路和无线模块将收集到的语音指令传输给机器人狗。机器人狗配备了语音识别模块,能够分析接收到的指令并执行相应的动作。值得强调的是,如图1a所示的传感器具有多个显著特征,包括小巧的体积、柔软性、亲肤性和耐用性。这些特性使SAAS能够紧密贴合皮肤,即使在日常活动中也能确保稳定运行。图1b中的爆炸视图详细展示了传感系统的整体结构。该系统由柔性印刷电路板(FPCB)、电子元件、压电微型超声换能器(PMUT)、蓝牙低功耗(BLE)模块、可充电电池以及柔性硅胶封装层组成。
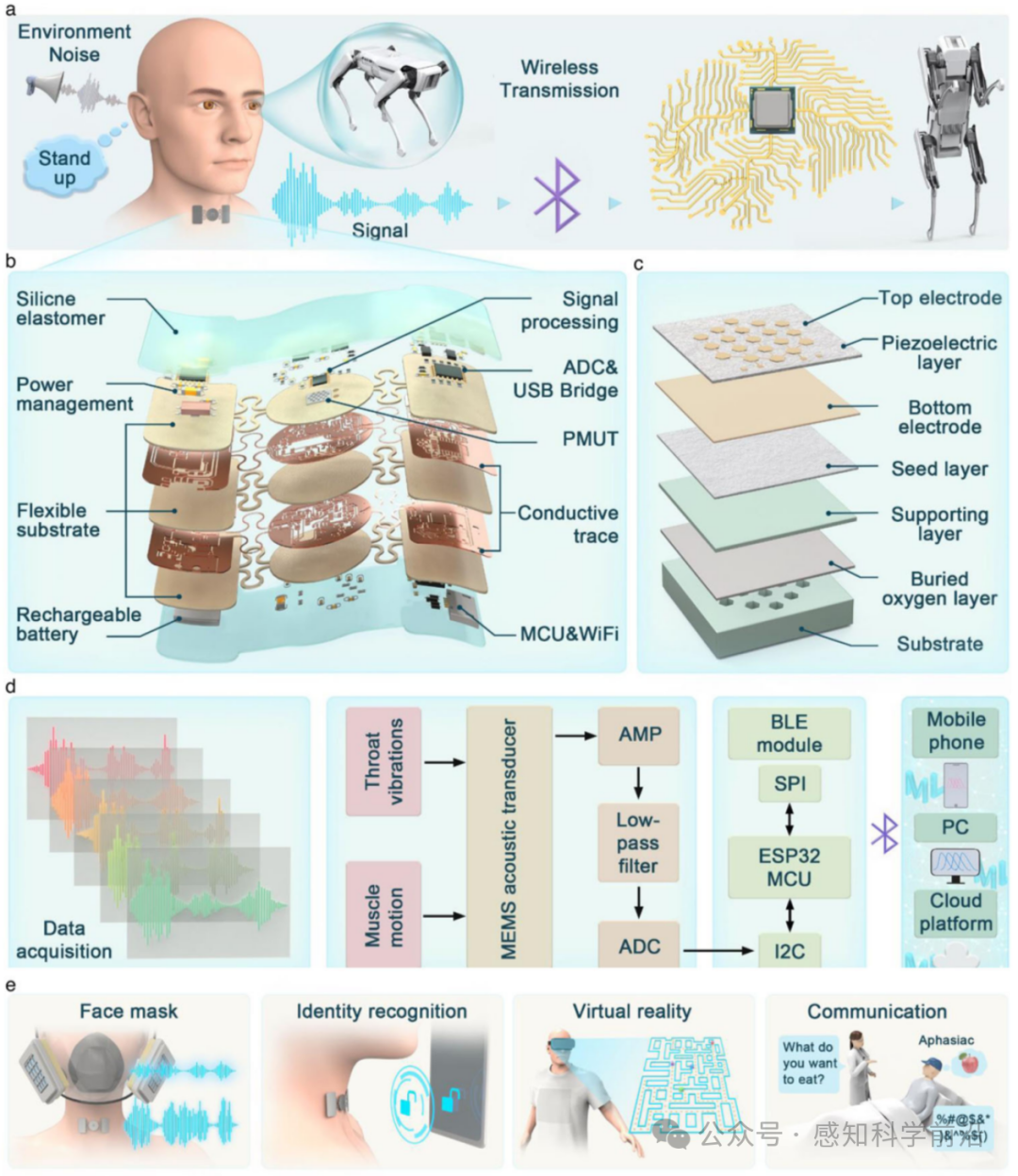
图1 用于在恶劣声学环境中进行语音识别的无线、柔性、可附加的声学传感器。a 语音识别系统的示意图,以实现人机交互。 b 可附加声学传感系统的爆炸视图。 c PMUT的结构示意图。 d 处理声带振动和肌肉运动信号的步骤流程图,包括信号处理、控制、无线通信和显示终端。 e SAAS在语音识别和交互中的应用示意图。
3.2 器件的设计原理与表征
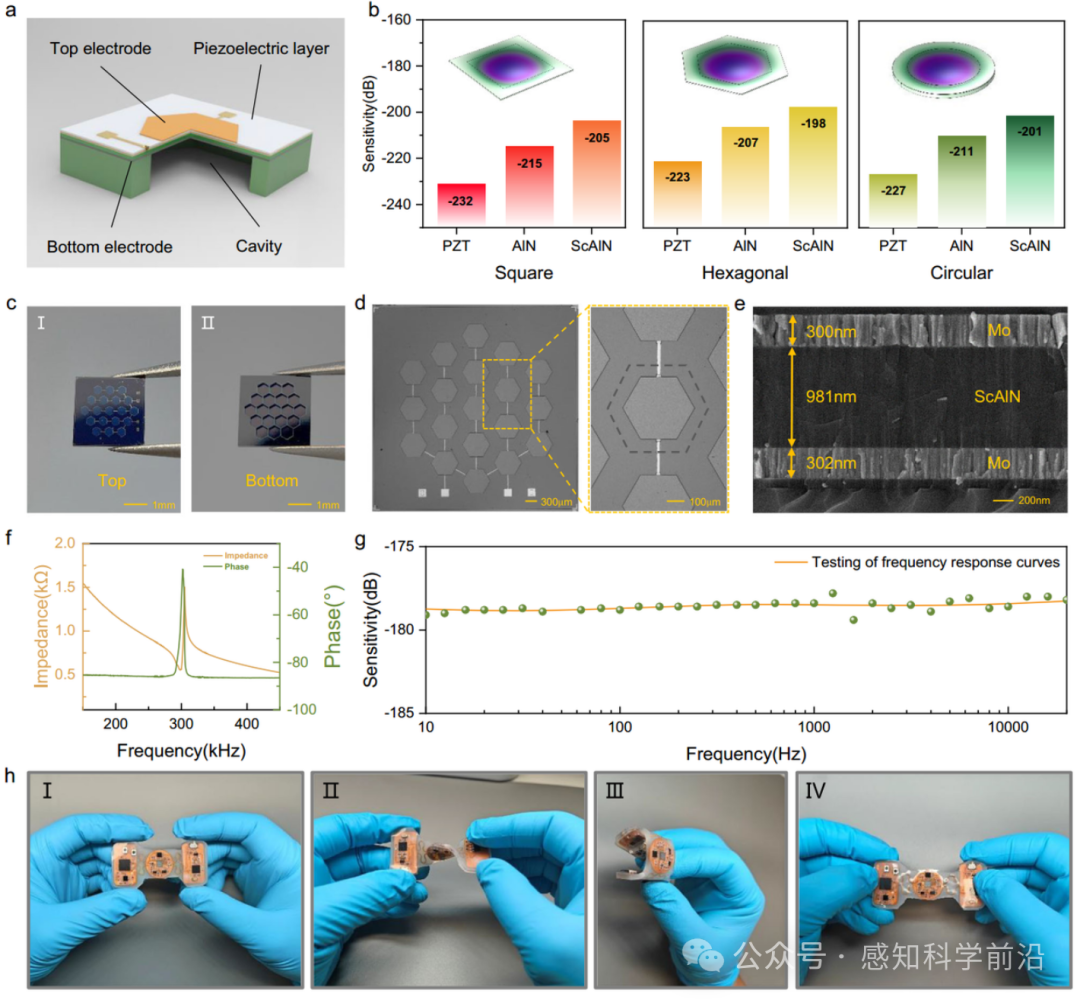
图 2 设备的设计原理与表征。a 基于 SOI 晶圆的声学传感器三维结构的横截面视图。b PZT、AlN、ScAlN 声学传感器及其对应三种形状的相关参数有限元仿真比较。c PMUT 的正面 (I) 和背面 (II) 照片。d 制备的声学芯片的光学显微镜图像及微元件的特写细节。e 制备的声学芯片的 Mo/ScAlN/Mo 薄膜结构的SEM横截面视图。f MEMS 芯片在空气中的电阻抗幅值和相位的谐振频率响应。g 封装 MEMS 传感器在水中低频宽带范围的灵敏度测试曲线。h 在未变形 (I)、扭曲 (II)、弯曲 (III) 和拉伸 (IV) 状态下的柔性设备图像展示。
3.3 抗干扰语音识别

图3 恶劣声学环境下语音检测的对比实验。a 同一对比测试在安静环境(I)、嘈杂环境(II)和佩戴口罩(III)下的照片。b 当参与者在安静环境(I)、嘈杂环境(II)和佩戴口罩(III)下说出“CQU”时,SAAS显示了声音信号的时域波形和频谱信息。c 当参与者在安静环境(I)、嘈杂环境(II)和佩戴口罩(III)下说出“CQU”时,商用参考麦克风显示了声音信号的时域波形和频谱信息。 d 测试对象在9种喉部附着位置和动作下的照片。 e 在9种喉部附着位置和动作下通过SAAS说出“Perfect”时获得的时域波形。
3.4 语音识别与身份认证
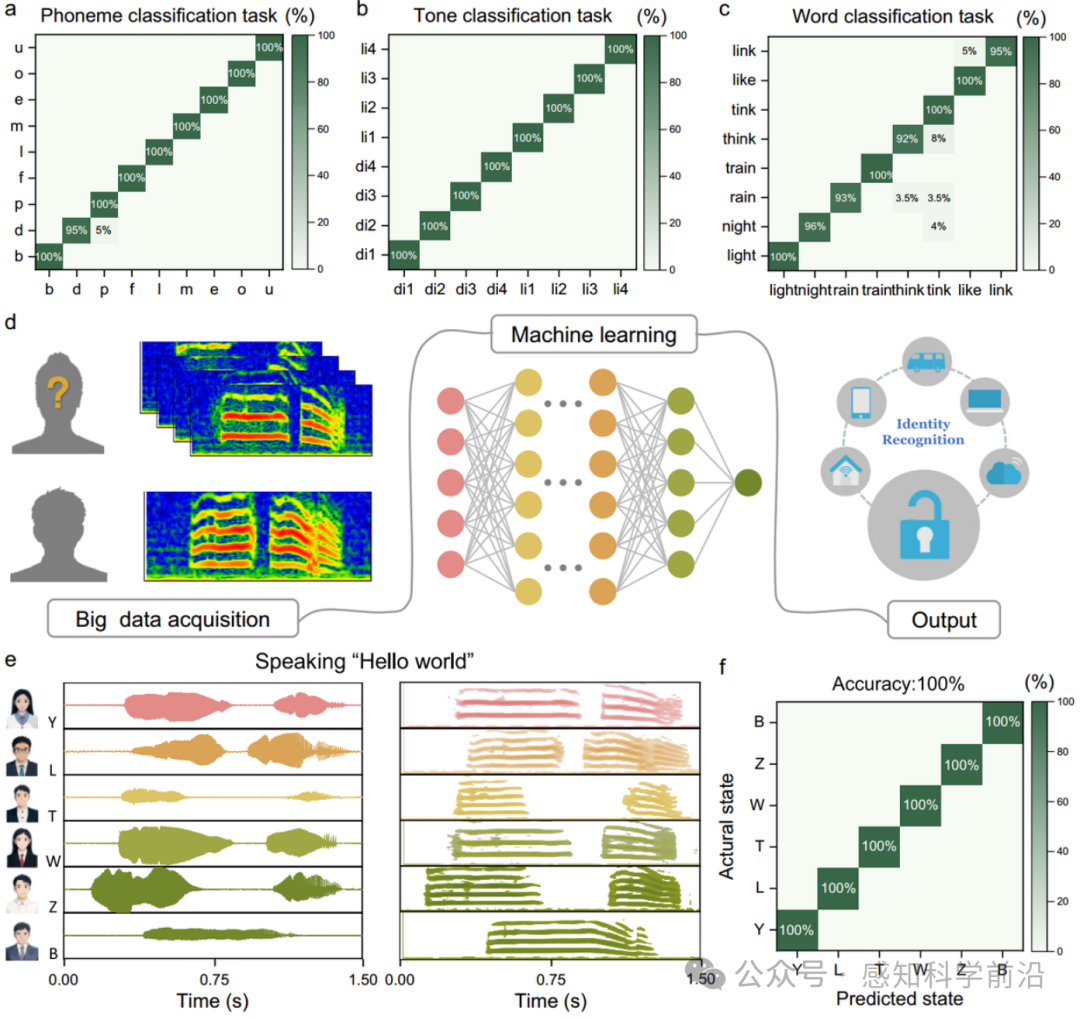
图4 基于SAAS的身份识别示例。a–c 音素、声调和相似发音词分类任务的混淆矩阵。d 通过数据收集、深度学习和实时显示实现的身份识别系统示意图。e 不同参与者在说“你好,世界”时的声学信息。f 身份识别的混淆矩阵。
3.5 人机交互

图5 使用软件即服务(SAAS)控制虚拟游戏和机器狗。a 实时无线人机交互(HMI)控制系统示意图。b 在吃豆人游戏中演示“上”“下”“左”“右”语音指令。c 通过语音指令对机器狗进行远程无线控制以执行动作:“站起来”“跳舞”“侧翻”“爬楼梯”
3.6 涉及语言障碍者的语音交互
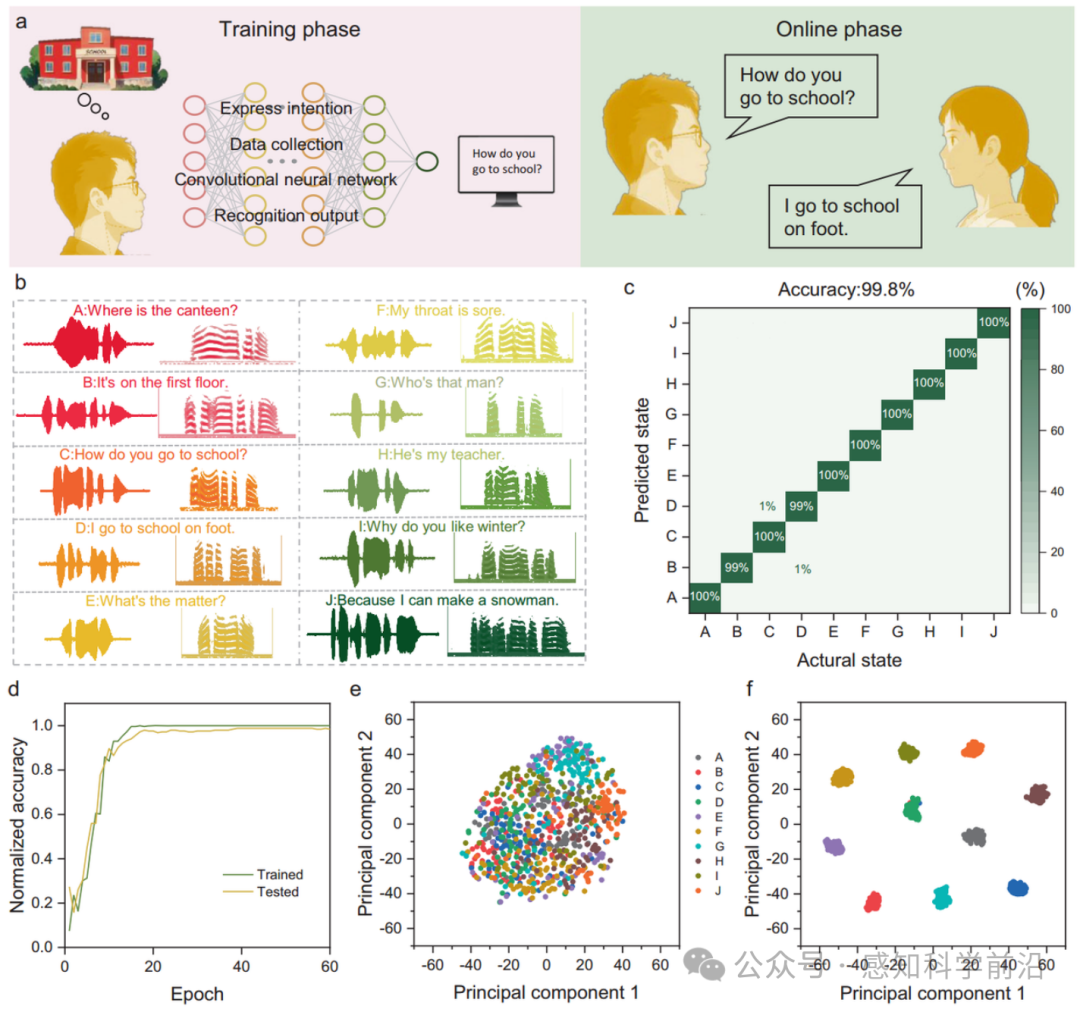
图6 基于SAAS的语音识别系统在人际交互中的应用。a 通过数据处理、分类和实时显示实现的交互系统示意图。b 使用卷积神经网络对从参与者收集的日常对话中分类出的10个句子样本的波形图和相应的频谱图。c 句子识别任务的混淆矩阵。d 60个训练周期迭代过程中训练数据和测试数据的归一化准确率。e T-SNE算法处理60次迭代后的特征向量矩阵。f T-SNE算法处理60次迭代后的特征向量矩阵。
四、全文总结
五、文献信息

声明:以上内容仅代表译者个人观点,译者水平有限,如有不准确之处,请在评论区留言指正!
服务:本平台免费提供相关领域的论文宣传。期待与您的交流与合作!
感知科学前沿
投稿、合作、加入交流群
flexible_sensor@foxmail.com