一、三大颠覆性突破
-
全能战士:语音转录、跨语言问答、场景识别、情感分析、实时对话一网打尽
-
工业级精度:1300万小时多语言音频训练,中文场景错误率吊打竞品
-
极速响应:首创分块流式解码,语音生成延迟低于500ms
二、技术宅必看黑科技
-
混合编码架构:12.5Hz高频语义捕捉+Whisper声学特征提取,听懂弦外之音
-
双模态生成:基于Qwen2.5-7B的并行输出头,文字/语音同步生成
-
开源大礼包:模型权重、训练代码、评测工具全公开(GitHub搜Kimi-Audio)
三、新颖的架构设计
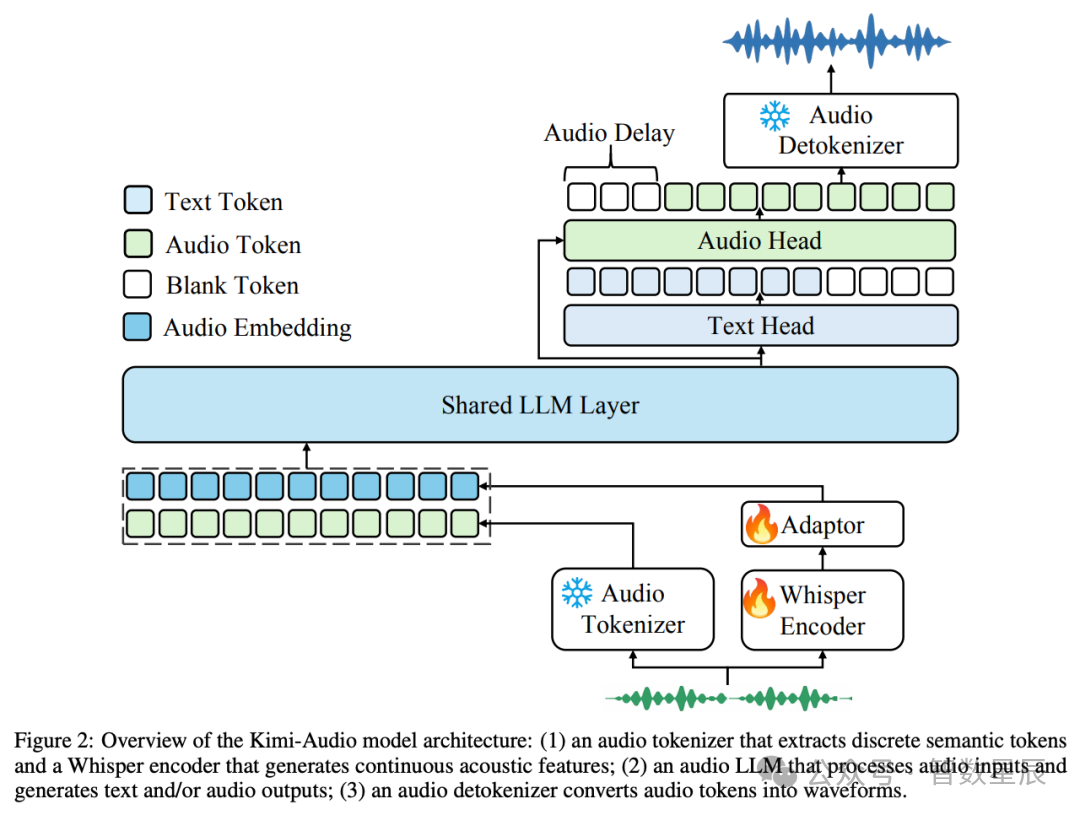
-
Audio Tokenizer: 将输入音频转换为:使用向量量化的离散语义标记(12.5Hz)。从 Whisper 编码器获得的连续声学特征(降采样至 12.5Hz)。
-
Audio LLM: 基于转换器的模型(从 Qwen 2.5 7B 等预先训练好的文本 LLM 初始化),具有处理多模态输入的共享层,然后是并行头,用于自回归生成文本标记和离散音频语义标记。
-
Audio Detokenizer: 使用流匹配模型和声码器(BigVGAN)将预测的离散语义音频标记转换成高保真波形,支持采用前瞻机制的分块流,以降低延迟。
四、模型评估
模型支持多种音频相关任务,包括但不限于:语音识别(ASR)、音频问答 (AQA)、音频字幕 (AAC)、语音情感识别 (SER)、声音事件 / 场景分类 (SEC/ASC)、文本到语音 (TTS)、语音转换 (VC) 以及端到端语音对话。
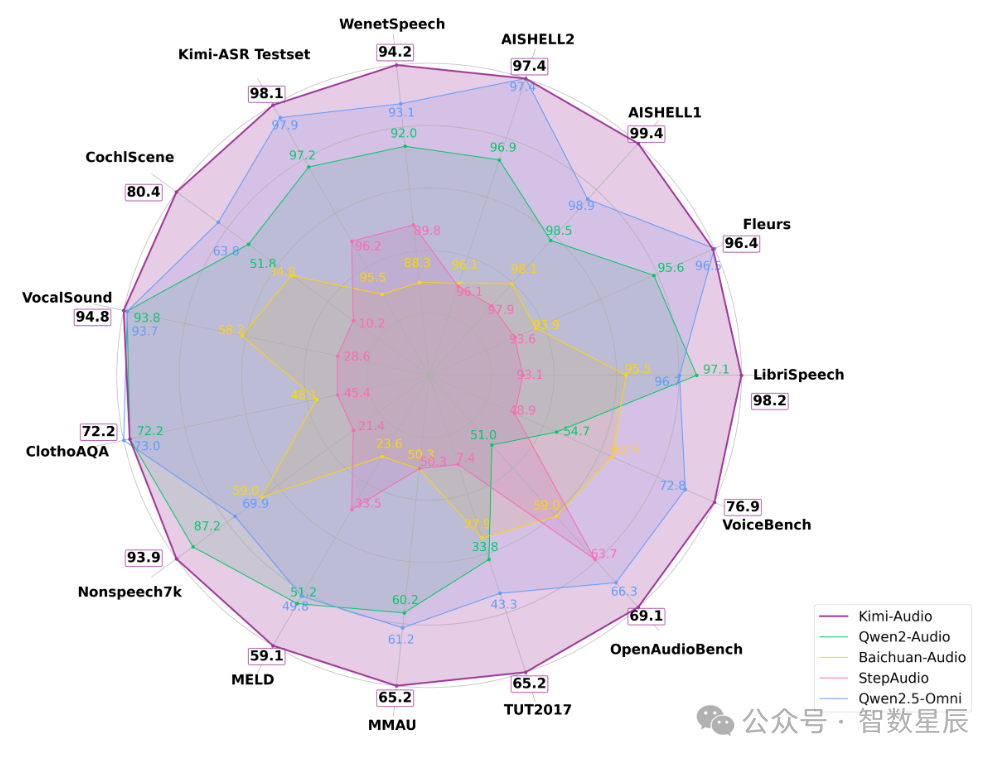
实测显示,这款模型在LibriSpeech等15个权威测试中横扫SOTA,普通话识别错误率仅0.6%,语音情绪识别准确率暴涨30%,堪称音频界的"六边形战士"。
自动语音识别(ASR)
研究者对 Kimi-Audio 的自动语音识别(ASR)能力进行了评估,涵盖了多种语言和声学条件的多样化数据集。如表 4 所示,Kimi-Audio 在这些数据集上持续展现出比以往模型更优越的性能。他们报告了这些数据集上的词错误率(WER),其中较低的值表示更好的性能。
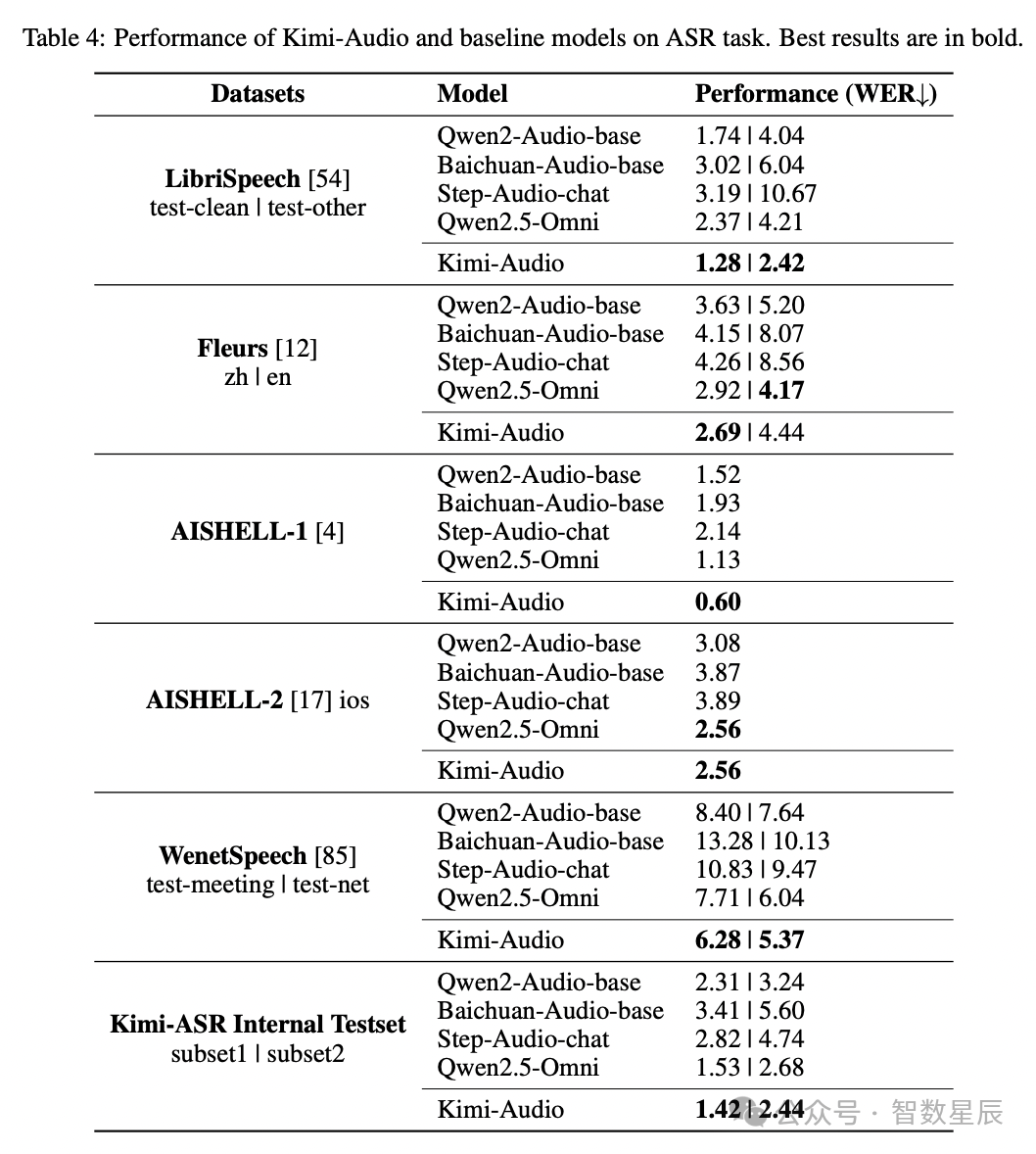
值得注意的是,Kimi-Audio 在广泛使用的 LibriSpeech 基准测试中取得了最佳结果,在 test-clean 上达到了 1.28 的错误率,在 test-other 上达到了 2.42,显著超越了像 Qwen2-Audio-base 和 Qwen2.5-Omni 这样的模型。在普通话 ASR 基准测试中,Kimi-Audio 在 AISHELL-1(0.60)和 AISHELL-2 ios(2.56)上创下了最先进的结果。此外,它在具有挑战性的 WenetSpeech 数据集上表现出色,在 test-meeting 和 test-net 上均取得了最低的错误率。最后,研究者在内部的 Kimi-ASR 测试集上的评估确认了该模型的鲁棒性。这些结果表明,Kimi-Audio 在不同领域和语言中均具有强大的 ASR 能力。
音频理解
除了语音识别外,研究者还评估了 Kimi-Audio 理解包括音乐、声音事件和语音在内的各种音频信号的能力。表 5 总结了在各种音频理解基准测试上的性能,通常较高的分数表示更好的性能。
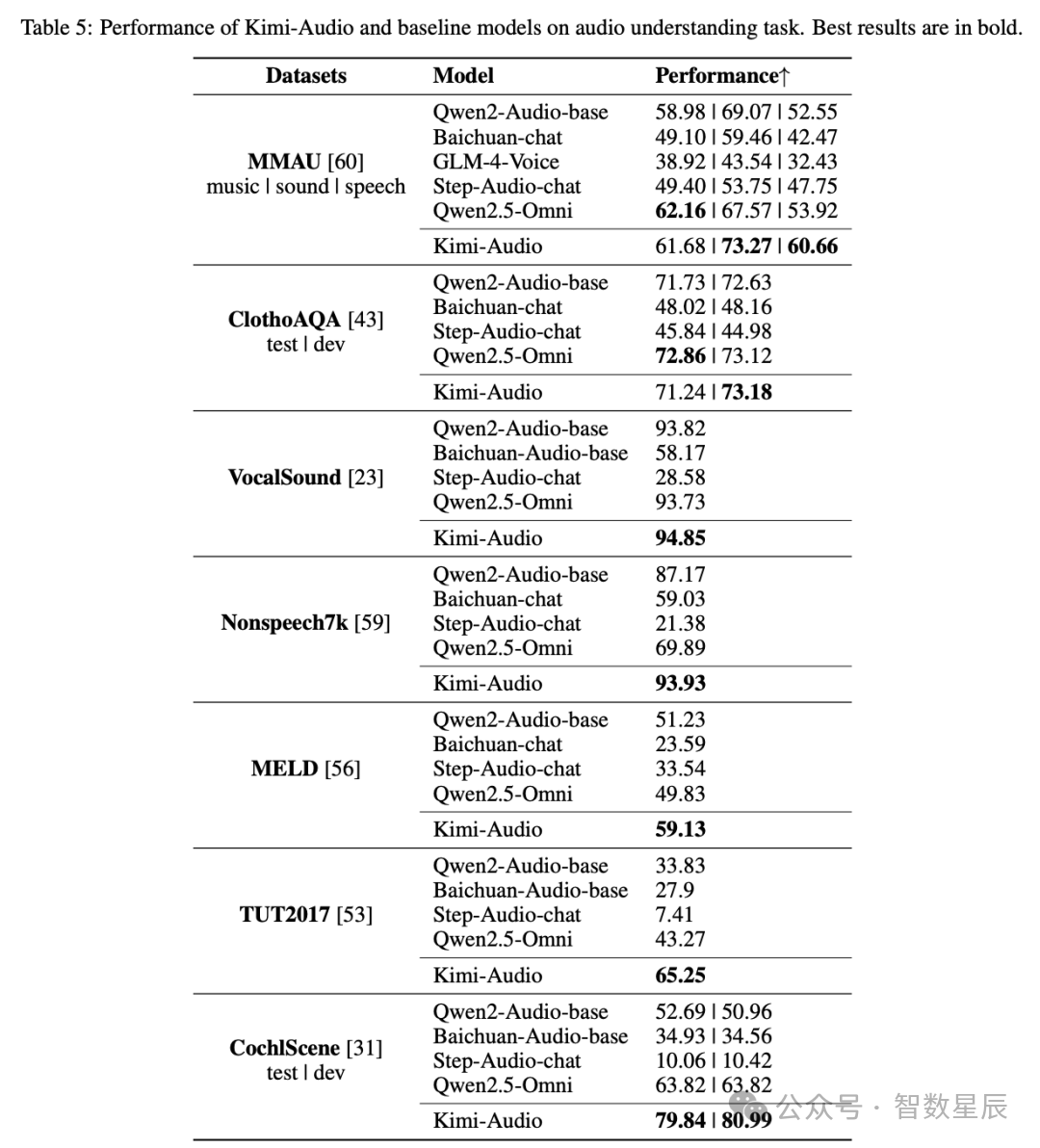
在 MMAU 基准测试中,Kimi-Audio 在声音类别(73.27)和语音类别(60.66)上展现出卓越的理解能力。同样,在 MELD 语音情感理解任务上,它也以 59.13 的得分超越了其他模型。Kimi-Audio 在涉及非语音声音分类(VocalSound 和 Nonspeech7k )以及声学场景分类(TUT2017 和 CochlScene)的任务中也处于领先地位。这些结果突显了 Kimi-Audio 在解读复杂声学信息方面的高级能力,超越了简单的语音识别范畴。
音频到文本聊天
研究者使用 OpenAudioBench 和 VoiceBench 基准测试 评估了 Kimi-Audio 基于音频输入进行文本对话的能力。这些基准测试评估了诸如指令遵循、问答和推理等各个方面。性能指标因基准测试而异,较高的分数表示更好的对话能力。结果如表 6 所示。
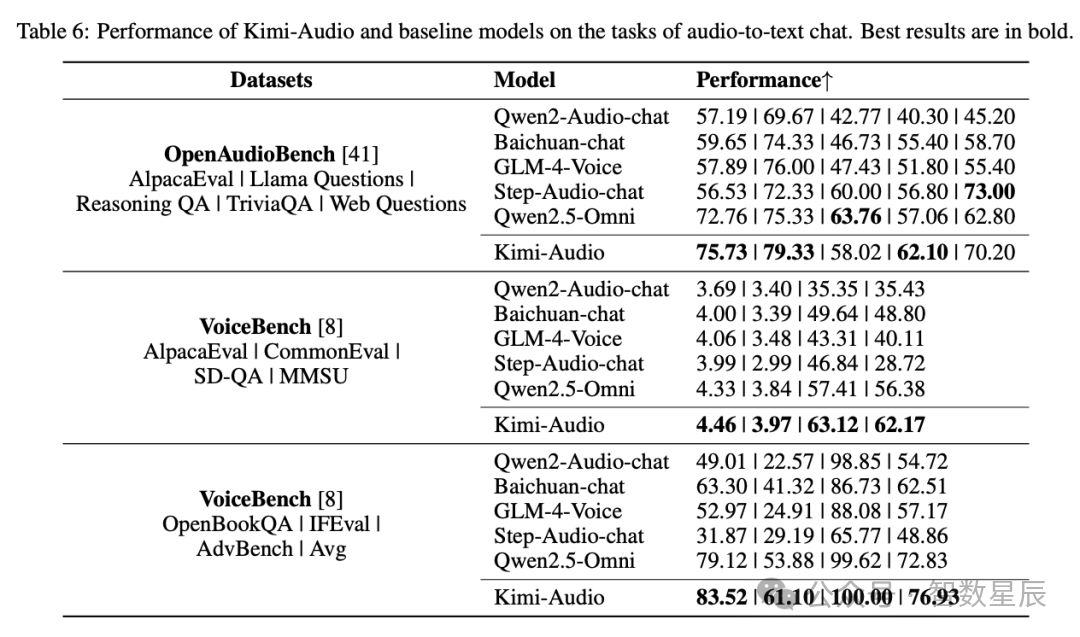
在 OpenAudioBench 上,Kimi-Audio 在多个子任务上实现了最先进的性能,包括 AlpacaEval、Llama Questions 和 TriviaQA,并在 Reasoning QA 和 Web Questions 上取得了极具竞争力的性能。VoiceBench 评估进一步证实了 Kimi-Audio 的优势。它在 AlpacaEval(4.46)、CommonEval(3.97)、SD-QA(63.12)、MMSU(62.17)、OpenBookQA(83.52)、Advbench(100.00)和 IFEval(61.10)上均持续超越所有对比模型。Kimi-Audio 在这些全面的基准测试中的整体表现证明了其在基于音频的对话和复杂推理任务中的卓越能力。
语音对话
除去 GPT-4o,Kimi-Audio 在情感控制、同理心和速度控制方面均取得了最高分。尽管 GLM-4-Voice 在口音控制方面表现略佳,但 Kimi-Audio 的整体平均得分仍高达 3.90,超过了 Step-Audio-chat(3.33)、GPT-4o-mini(3.45)和 GLM-4-Voice(3.65),并与 GPT-4o(4.06)仅存在微小差距。总体而言,评估结果表明,Kimi-Audio 在生成富有表现力和可控性的语音方面表现出色。
五、应用场景预警
-
企业级:智能客服语音质检准确率提升40%
-
开发者:5行代码实现多语言语音助手(附Python示例)
-
硬核玩家:二次开发打造专属AI声优
六、立即尝鲜(开发版):
安装:
pipinstall -r requirements.txt代码示例:
importsoundfileassffromkimia_infer.api.kimiaimportKimiAudioimporttorch# --- 1. 加载模型 ---# 从Hugging Face Hub加载模型(需先运行 huggingface-cli login 登录)model_id ="moonshotai/Kimi-Audio-7B-Instruct"# 官方模型IDdevice ="cuda"iftorch.cuda.is_available()else"cpu"# 自动检测设备try:# 尝试从Hugging Face加载模型model = KimiAudio(model_path=model_id, load_detokenizer=True)model.to(device) # 将模型移动到指定设备exceptExceptionase:print(f"自动加载失败,请检查网络连接或模型权限。错误信息:{e}")print(">>> 备用方案:使用本地模型(需提前下载)")# 本地模型路径示例(需用户自行替换)model_path ="/path/to/local/Kimi-Audio-7B"model = KimiAudio(model_path=model_path, load_detokenizer=True)model.to(device)# --- 2. 配置生成参数 ---generation_config = {"audio_temperature":0.8, # 音频生成温度(越高越随机)"audio_top_k":10, # 音频Token采样数量"text_temperature":0.0, # 文本生成温度(0表示确定性输出)"text_top_k":5, # 文本Token采样数量"audio_repetition_penalty":1.0, # 音频重复惩罚因子"audio_repetition_window_size":64, # 音频重复检测窗口"text_repetition_penalty":1.0, # 文本重复惩罚因子"text_repetition_window_size":16, # 文本重复检测窗口}# --- 3. 示例1:语音转文本 ---# 准备测试音频(需用户自行准备或从示例库下载)asr_audio_path ="test_audios/asr_example.wav"# 中文语音示例# 构建对话格式输入messages = [{"role":"user","message_type":"text","content":"请转录以下语音:"},{"role":"user","message_type":"audio","content": asr_audio_path}]# 执行语音识别_, transcription = model.generate(messages=messages,output_type="text",**generation_config)print(">>> 语音识别结果:", transcription) # 示例输出:"这并不是告别,这是一个篇章的结束,也是新篇章的开始。"# --- 4. 示例2:语音对话 ---qa_audio_path ="test_audios/qa_example.wav"# 问题语音示例# 构建语音对话输入conversation = [{"role":"user","message_type":"audio","content": qa_audio_path}]# 生成语音+文本回复response_audio, response_text = model.generate(messages=conversation,output_type="both",**generation_config)# 保存生成的语音output_path ="AI回复.wav"sf.write(output_path,response_audio.detach().cpu().view(-1).numpy(), # 转换Tensor为numpy数组24000# 采样率24kHz)print(f">>> AI语音回复已保存至:{output_path}")print(">>> AI文本回复:", response_text) # 示例输出:"当然,我很乐意帮助您解决这个问题。"print("Kimi-Audio 示例运行完成!")
七、结语当Siri还在纠结"打开空调"的指令,当客服机器人重复着生硬话术,Kimi-Audio的横空出世,正在撕开语音交互的天花板。这个1300万小时音频炼成的"六边形战士",不仅把开源社区的军备竞赛推向新高度,更预示着一个更智能的语音交互时代:
你的耳机将听懂哽咽背后的焦虑跨国会议无需同传实时转录短视频配音只需输入文案